GraphQL
GraphQL is a fundamental part of Redwood. Having said that, you can get going without knowing anything about it, and can actually get quite far without ever having to read the docs. But to master Redwood, you'll need to have more than just a vague notion of what GraphQL is. You'll have to really grok it.
GraphQL 101
GraphQL is a query language that enhances the exchange of data between clients (in Redwood's case, a React app) and servers (a Redwood API).
Unlike a REST API, a GraphQL Client performs operations that allow gathering a rich dataset in a single request. There's three types of GraphQL operations, but here we'll only focus on two: Queries (to read data) and Mutations (to create, update, or delete data).
The following GraphQL query:
query GetProject {
project(name: "GraphQL") {
id
title
description
owner {
id
username
}
tags {
id
name
}
}
}
returns the following JSON response:
{
"data": {
"project": {
"id": 1,
"title": "My Project",
"description": "Lorem ipsum...",
"owner": {
"id": 11,
"username": "Redwood",
},
"tags": [
{ "id": 22, "name": "graphql" }
]
}
},
"errors": null
}
Notice that the response's structure mirrors the query's. In this way, GraphQL makes fetching data descriptive and predictable.
Again, unlike a REST API, a GraphQL API is built on a schema that specifies exactly which queries and mutations can be performed.
For the GetProject query above, here's the schema backing it:
type Project {
id: ID!
title: String
description: String
owner: User!
tags: [Tag]
}
# ... User and Tag type definitions
type Query {
project(name: String!): Project
}
More information on GraphQL types can be found in the official GraphQL documentation.
Finally, the GraphQL schema is associated with a resolvers map that helps resolve each requested field. For example, here's what the resolver for the owner field on the Project type may look like:
export const Project = {
owner: (args, { root, context, info }) => {
return db.project.findUnique({ where: { id: root.id } }).user()
},
// ...
}
You can read more about resolvers in the dedicated Understanding Default Resolvers section below.
To summarize, when a GraphQL query reaches a GraphQL API, here's what happens:
+--------------------+ +--------------------+
| | 1.send operation | |
| | | GraphQL Server |
| GraphQL Client +----------------->| | |
| | | | 2.resolve |
| | | | data |
+--------------------+ | v |
^ | +----------------+ |
| | | | |
| | | Resolvers | |
| | | | |
| | +--------+-------+ |
| 3. respond JSON with data | | |
+-----------------------------+ <--------+ |
| |
+--------------------+
In contrast to most GraphQL implementations, Redwood provides a "deconstructed" way of creating a GraphQL API:
- You define your SDLs (schema) in
*.sdl.jsfiles, which define what queries and mutations are available, and what fields can be returned - For each query or mutation, you write a service function with the same name. This is the resolver
- Redwood then takes all your SDLs and Services (resolvers), combines them into a GraphQL server, and expose it as an endpoint
RedwoodJS and GraphQL
Besides taking care of the annoying stuff for you (namely, mapping your resolvers, which gets annoying fast if you do it yourself!), there's not many gotchas with GraphQL in Redwood. The only Redwood-specific thing you should really be aware of is resolver args.
Since there's two parts to GraphQL in Redwood, the client and the server, we've divided this doc up that way.
On the web side, Redwood uses Apollo Client by default though you can swap it out for something else if you want.
The api side offers a GraphQL server built on GraphQL Yoga and the Envelop plugin system from The Guild.
Redwood's api side is "serverless first", meaning it's architected as functions which can be deployed on either serverless or traditional infrastructure, and Redwood's GraphQL endpoint is effectively "just another function" (with a whole lot more going on under the hood, but that part is handled for you, out of the box). One of the tenets of the Redwood philosophy is "Redwood believes that, as much as possible, you should be able to operate in a serverless mindset and deploy to a generic computational grid.”
GraphQL Yoga and the Generic Computation Grid
To be able to deploy to a “generic computation grid” means that, as a developer, you should be able to deploy using the provider or technology of your choosing. You should be able to deploy to Netlify, Vercel, Fly, Render, AWS Serverless, or elsewhere with ease and no vendor or platform lock in. You should be in control of the framework, what the response looks like, and how your clients consume it.
The same should be true of your GraphQL Server. GraphQL Yoga from The Guild makes that possible.
The fully-featured GraphQL Server with focus on easy setup, performance and great developer experience.
RedwoodJS leverages Yoga's Envelop plugins to implement custom internal plugins to help with authentication, logging, directive handling, and more.
Security Best Practices
RedwoodJS implements GraphQL Armor from Escape Technologies to make your endpoint more secure by default by implementing common GraphQL security best practices.
GraphQL Armor, developed by Escape in partnership with The Guild, is a middleware for JS servers that adds a security layer to the RedwoodJS GraphQL endpoint.
Conclusion
All this gets us closer to Redwood's goal of being able to deploy to a "generic computation grid". And that’s exciting!
Client-side
RedwoodApolloProvider
By default, Redwood Apps come ready-to-query with the RedwoodApolloProvider. As you can tell from the name, this Provider wraps ApolloProvider. Omitting a few things, this is what you'll normally see in Redwood Apps:
import { RedwoodApolloProvider } from '@redwoodjs/web/apollo'
// ...
const App = () => (
<RedwoodApolloProvider>
<Routes />
</RedwoodApolloProvider>
)
// ...
You can use Apollo's useQuery and useMutation hooks by importing them from @redwoodjs/web, though if you're using useQuery, we recommend that you use a Cell:
import { useMutation } from '@redwoodjs/web'
const MUTATION = gql`
# your mutation...
`
const MutateButton = () => {
const [mutate] = useMutation(MUTATION)
return (
<button onClick={() => mutate({ ... })}>
Click to mutate
</button>
)
}
Note that you're free to use any of Apollo's other hooks, you'll just have to import them from @apollo/client instead. In particular, these two hooks might come in handy:
| Hook | Description |
|---|---|
| useLazyQuery | Execute queries in response to events other than component rendering |
| useApolloClient | Access your instance of ApolloClient |
Customizing the Apollo Client and Cache
By default, RedwoodApolloProvider configures an ApolloClient instance with 1) a default instance of InMemoryCache to cache responses from the GraphQL API and 2) an authMiddleware to sign API requests for use with Redwood's built-in auth. Beyond the cache and link params, which are used to set up that functionality, you can specify additional params to be passed to ApolloClient using the graphQLClientConfig prop. The full list of available configuration options for the client are documented here on Apollo's site.
Depending on your use case, you may want to configure InMemoryCache. For example, you may need to specify a type policy to change the key by which a model is cached or to enable pagination on a query. This article from Apollo explains in further detail why and how you might want to do this.
To configure the cache when it's created, use the cacheConfig property on graphQLClientConfig. Any value you pass is passed directly to InMemoryCache when it's created.
For example, if you have a query named search that supports Apollo's offset pagination, you could enable it by specifying:
<RedwoodApolloProvider graphQLClientConfig={{
cacheConfig: {
typePolicies: {
Query: {
fields: {
search: {
// Uses the offsetLimitPagination preset from "@apollo/client/utilities";
...offsetLimitPagination()
}
}
}
}
}
}}>
Swapping out the RedwoodApolloProvider
As long as you're willing to do a bit of configuring yourself, you can swap out RedwoodApolloProvider with your GraphQL Client of choice. You'll just have to get to know a bit of the make up of the RedwoodApolloProvider; it's actually composed of a few more Providers and hooks:
FetchConfigProvideruseFetchConfigGraphQLHooksProvider
For an example of configuring your own GraphQL Client, see the redwoodjs-react-query-provider. If you were thinking about using react-query, you can also just go ahead and install it!
Note that if you don't import RedwoodApolloProvider, it won't be included in your bundle, dropping your bundle size quite a lot!
Server-side
Understanding Default Resolvers
According to the spec, for every field in your sdl, there has to be a resolver in your Services. But you'll usually see fewer resolvers in your Services than you technically should. And that's because if you don't define a resolver, GraphQL Yoga server will.
The key question the Yoga server asks is: "Does the parent argument (in Redwood apps, the parent argument is named root—see Redwood's Resolver Args) have a property with this resolver's exact name?" Most of the time, especially with Prisma Client's ergonomic returns, the answer is yes.
Let's walk through an example. Say our sdl looks like this:
export const schema = gql`
type User {
id: Int!
email: String!
name: String
}
type Query {
users: [User!]!
}
`
So we have a User model in our schema.prisma that looks like this:
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
}
If you create your Services for this model using Redwood's generator (yarn rw g service user), your Services will look like this:
import { db } from 'src/lib/db'
export const users = () => {
return db.user.findMany()
}
Which begs the question: where are the resolvers for the User fields—id, email, and name?
All we have is the resolver for the Query field, users.
As we just mentioned, GraphQL Yoga defines them for you. And since the root argument for id, email, and name has a property with each resolvers' exact name (i.e. root.id, root.email, root.name), it'll return the property's value (instead of returning undefined, which is what Yoga would do if that weren't the case).
But, if you wanted to be explicit about it, this is what it would look like:
import { db } from 'src/lib/db'
export const users = () => {
return db.user.findMany()
}
export const Users = {
id: (_args, { root }) => root.id,
email: (_args, { root }) => root.email,
name: (_args, { root }) => root.name,
}
The terminological way of saying this is, to create a resolver for a field on a type, in the Service, export an object with the same name as the type that has a property with the same name as the field.
Sometimes you want to do this since you can do things like add completely custom fields this way:
export const Users = {
id: (_args, { root }) => root.id,
email: (_args, { root }) => root.email,
name: (_args, { root }) => root.name,
age: (_args, { root }) => new Date().getFullYear() - root.birthDate.getFullYear()
}
Redwood's Resolver Args
According to the spec, resolvers take four arguments: args, obj, context, and info. In Redwood, resolvers do take these four arguments, but what they're named and how they're passed to resolvers is slightly different:
argsis passed as the first argumentobjis namedroot(all the rest keep their names)root,context, andinfoare wrapped into an object,gqlArgs; this object is passed as the second argument
Here's an example to make things clear:
export const Post = {
user: (args, gqlArgs) => db.post.findUnique({ where: { id: gqlArgs?.root.id } }).user(),
}
Of the four, you'll see args and root being used a lot.
| Argument | Description |
|---|---|
args | The arguments provided to the field in the GraphQL query |
root | The previous return in the resolver chain |
context | Holds important contextual information, like the currently logged in user |
info | Holds field-specific information relevant to the current query as well as the schema details |
There's so many terms!
Half the battle here is really just coming to terms. To keep your head from spinning, keep in mind that everybody tends to rename
objto something else: Redwood calls itroot, GraphQL Yoga calls itparent.objisn't exactly the most descriptive name in the world.
Context
In Redwood, the context object that's passed to resolvers is actually available to all your Services, whether or not they're serving as resolvers. Just import it from @redwoodjs/graphql-server:
import { context } from '@redwoodjs/graphql-server'
How to Modify the Context
Because the context is read-only in your services, if you need to modify it, then you need to do so in the createGraphQLHandler.
To populate or enrich the context on a per-request basis with additional attributes, set the context attribute createGraphQLHandler to a custom ContextFunction that modifies the context.
For example, if we want to populate a new, custom ipAddress attribute on the context with the information from the request's event, declare the setIpAddress ContextFunction as seen here:
// ...
const ipAddress = ({ event }) => {
return event?.headers?.['client-ip'] || event?.requestContext?.identity?.sourceIp || 'localhost'
}
const setIpAddress = async ({ event, context }) => {
context.ipAddress = ipAddress({ event })
}
export const handler = createGraphQLHandler({
getCurrentUser,
loggerConfig: {
logger,
options: { operationName: true, tracing: true },
},
schema: makeMergedSchema({
schemas,
services,
}),
context: setIpAddress,
onException: () => {
// Disconnect from your database with an unhandled exception.
db.$disconnect()
},
})
Note: If you use the preview GraphQL Yoga/Envelop
graphql-serverpackage and a custom ContextFunction to modify the context in the createGraphQL handler, the function is provided only the context and not the event. However, theeventinformation is available as an attribute of the context ascontext.event. Therefore, in the above example, one would fetch the ip address from the event this way:ipAddress({ event: context.event }).
The Root Schema
Did you know that you can query redwood? Try it in the GraphQL Playground (you can find the GraphQL Playground at http://localhost:8911/graphql when your dev server is running—yarn rw dev api):
query {
redwood {
version
currentUser
}
}
How is this possible? Via Redwood's root schema. The root schema is where things like currentUser are defined:
scalar BigInt
scalar Date
scalar Time
scalar DateTime
scalar JSON
scalar JSONObject
type Redwood {
version: String
currentUser: JSON
prismaVersion: String
}
type Query {
redwood: Redwood
}
Now that you've seen the sdl, be sure to check out the resolvers:
export const resolvers: Resolvers = {
BigInt: BigIntResolver,
Date: DateResolver,
Time: TimeResolver,
DateTime: DateTimeResolver,
JSON: JSONResolver,
JSONObject: JSONObjectResolver,
Query: {
redwood: () => ({
version: redwoodVersion,
prismaVersion: prismaVersion,
currentUser: (_args: any, context: GlobalContext) => {
return context?.currentUser
},
}),
},
}
CORS Configuration
CORS stands for Cross Origin Resource Sharing; in a nutshell, by default, browsers aren't allowed to access resources outside their own domain.
Let's say you're hosting each of your Redwood app's sides on different domains: the web side on www.example.com and the api side (and thus, the GraphQL Server) on api.example.com.
When the browser tries to fetch data from the /graphql function, you'll see an error that says the request was blocked due to CORS. Wording may vary, but it'll be similar to:
⛔️ Access to fetch ... has been blocked by CORS policy: Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource.
To fix this, you need to "configure CORS" by adding:
'Access-Control-Allow-Origin': 'https://example.com'
'Access-Control-Allow-Credentials': true
to the GraphQL response headers which you can do this by setting the cors option in api/src/functions/graphql.{js|t}s:
export const handler = createGraphQLHandler({
loggerConfig: { logger, options: {} },
directives,
sdls,
services,
cors: {
// 👈 setup your CORS configuration options
origin: '*',
credentials: true,
},
onException: () => {
// Disconnect from your database with an unhandled exception.
db.$disconnect()
},
})
For more in-depth discussion and configuration of CORS when it comes to using a cookie-based auth system (like dbAuth), see the CORS documentation.
Health Checks
You can use health checks to determine if a server is available and ready to start serving traffic. For example, services like Pingdom use health checks to determine server uptime and will notify you if it becomes unavailable.
Redwood's GraphQL server provides a health check endpoint at /graphql/health as part of its GraphQL handler.
If the server is healthy and can accept requests, the response will contain the following headers:
content-type: application/json
server: GraphQL Yoga
x-yoga-id: yoga
and will return a HTTP/1.1 200 OK status with the body:
{
"message": "alive"
}
Note the x-yoga-id header. The header's value defaults to yoga when healthCheckId isn't set in createGraphQLHandler. But you can customize it when configuring your GraphQL handler:
// ...
export const handler = createGraphQLHandler({
// This will be the value of the `x-yoga-id` header
healthCheckId: 'my-redwood-graphql-server',
getCurrentUser,
loggerConfig: { logger, options: {} },
directives,
sdls,
services,
onException: () => {
// Disconnect from your database with an unhandled exception.
db.$disconnect()
},
})
If the health check fails, then the GraphQL server is unavailable and you should investigate what could be causing the downtime.
Perform a Health Check
To perform a health check, make a HTTP GET request to the /graphql/health endpoint.
For local development,
with the proxy using curl from the command line:
curl "http://localhost:8910/.redwood/functions/graphql/health" -i
or by directly invoking the graphql function:
curl "http://localhost:8911/graphql/health" -i
you should get the response:
{
"message": "alive"
}
For production, make a request wherever your /graphql function exists.
These examples use
curlbut you can perform a health check via any HTTP GET request.
Perform a Readiness Check
A readiness check confirms that your GraphQL server can accept requests and serve your server's traffic.
It forwards a request to the health check with a header that must match your healthCheckId in order to succeed.
If the healthCheckId doesn't match or the request fails, then your GraphQL server isn't "ready".
To perform a readiness check, make a HTTP GET request to the /graphql/readiness endpoint with the appropriate healthCheckId header.
For local development, you can make a request to the proxy:
curl "http://localhost:8910/.redwood/functions/graphql/readiness" \
-H 'x-yoga-id: yoga' \
-i
or directly invoke the graphql function:
curl "http://localhost:8911/graphql/readiness" \
-H 'x-yoga-id: yoga' \
-i
Either way, you should get a 200 OK HTTP status if ready, or a 503 Service Unavailable if not.
For production, make a request wherever your /graphql function exists.
These examples use
curlbut you can perform a readiness check via any HTTP GET request with the proper headers.
Verifying GraphQL Schema
In order to keep your GraphQL endpoint and services secure, you must specify one of @requireAuth, @skipAuth or a custom directive on every query and mutation defined in your SDL.
Redwood will verify that your schema complies with these runs when:
- building (or building just the api)
- launching the dev server.
If any fail this check, you will see:
- each query of mutation listed in the command's error log
- a fatal error
⚠️ GraphQL server crashedif launching the server
Build-time Verification
When building via the yarn rw build command and the SDL fails verification, you will see output that lists each query or mutation missing the directive:
✔ Generating Prisma Client...
✖ Verifying graphql schema...
→ - deletePost Mutation
Building API...
Cleaning Web...
Building Web...
Prerendering Web...
You must specify one of @requireAuth, @skipAuth or a custom directive for
- contacts Query
- posts Query
- post Query
- createContact Mutation
- createPost Mutation
- updatePost Mutation
- deletePost Mutation
Dev Server Verification
When launching the dev server via the yarn rw dev command, you will see output that lists each query or mutation missing the directive:
gen | Generating TypeScript definitions and GraphQL schemas...
gen | 37 files generated
api | Building... Took 444 ms
api | Starting API Server... Took 2 ms
api | Listening on http://localhost:8911/
api | Importing Server Functions...
web | ...
api | FATAL [2021-09-24 18:41:49.700 +0000]:
api | ⚠️ GraphQL server crashed
api |
api | Error: You must specify one of @requireAuth, @skipAuth or a custom directive for
api | - contacts Query
api | - posts Query
api | - post Query
api | - createContact Mutation
api | - createPost Mutation
api | - updatePost Mutation
api | - deletePost Mutation
To fix these errors, simple declare with @requireAuth to enforce authentication or @skipAuth to keep the operation public on each as appropriate for your app's permissions needs.
Custom Scalars
GraphQL scalar types give data meaning and validate that their values makes sense. Out of the box, GraphQL comes with Int, Float, String, Boolean and ID. While those can cover a wide variety of use cases, you may need more specific scalar types to better describe and validate your application's data.
For example, if there's a Person type in your schema that has a field like ageInYears, if it's actually supposed to represent a person's age, technically it should only be a positive integer—never a negative one.
Something like the PositiveInt scalar provides that meaning and validation.
Scalars vs Service vs Directives
How are custom scalars different from Service Validations or Validator Directives?
Service validations run when resolving the service. Because they run at the start of your Service function and throw if conditions aren't met, they're great for validating whenever you use a Service—anywhere, anytime. For example, they'll validate via GraphQL, Serverless Functions, webhooks, etc. Custom scalars, however, only validate via GraphQL and not anywhere else.
Service validations also perform more fine-grained checks than scalars which are more geared toward validating that data is of a specific type.
Validator Directives control user access to data and also whether or not a user is authorized to perform certain queries and/or mutations.
How To Add a Custom Scalar
Let's say that you have a Product type that has three fields: a name, a description, and the type of currency.
The built-in String scalar should suffice for the first two, but for the third, you'd be better off with a more-specific String scalar that only accepts ISO 4217 currency codes, like USD, EUR, CAD, etc.
Luckily there's already a Currency scalar type that does exactly that!
All you have to do is add it to your GraphQL schema.
To add a custom scalar to your GraphQL schema:
- Add the scalar definition to one of your sdl files, such as
api/src/graphql/scalars.sdl.ts
Note that you may have to create this file. Moreover, it's just a convention—custom scalar type definitions can be in any of your sdl files.
export const schema = gql`
scalar Currency
`
- Import the scalar's definition and resolver and pass them to your GraphQLHandler via the
schemaOptionsproperty:
import { CurrencyDefinition, CurrencyResolver } from 'graphql-scalars'
// ...
export const handler = createGraphQLHandler({
loggerConfig: { logger, options: {} },
directives,
sdls,
services,
schemaOptions: {
typeDefs: [CurrencyDefinition],
resolvers: { Currency: CurrencyResolver },
},
onException: () => {
// Disconnect from your database with an unhandled exception.
db.$disconnect()
},
})
- Use the scalar in your types
export const schema = gql`
type Product {
id: Int!
name: String!
description: String!
currency_iso_4217: Currency! // validate on query
createdAt: DateTime!
}
type Query {
products: [Product!]! @requireAuth
product(id: Int!): Product @requireAuth
}
input CreateProductInput {
name: String!
description: String!
currency_iso_4217: Currency! // validate on mutation
}
input UpdateProductInput {
name: String
description: String
currency_iso_4217: Currency // validate on mutation
}
type Mutation {
createProduct(input: CreateProductInput!): Product! @requireAuth
updateProduct(id: Int!, input: UpdateProductInput!): Product! @requireAuth
deleteProduct(id: Int!): Product! @requireAuth
}
`
Directives
Directives supercharge your GraphQL services. They add configuration to fields, types or operations that act like "middleware" that lets you run reusable code during GraphQL execution to perform tasks like authentication, formatting, and more.
You'll recognize a directive by its preceded by the @ character, e.g. @myDirective, and by being declared alongside a field:
type Bar {
name: String! @myDirective
}
or a Query or Mutation:
type Query {
bars: [Bar!]! @myDirective
}
type Mutation {
createBar(input: CreateBarInput!): Bar! @myDirective
}
Unions
Unions are abstract GraphQL types that enable a schema field to return one of multiple object types.
union FavoriteTree = Redwood | Ginkgo | Oak
A field can have a union as its return type.
type Query {
searchTrees: [FavoriteTree] // This list can include Redwood, Gingko or Oak objects
}
All of a union's included types must be object types and do not need to share any fields.
To query a union, you can take advantage on inline fragments to include subfields of multiple possible types.
query GetFavoriteTrees {
__typename // typename is helpful when querying a field that returns one of multiple types
searchTrees {
... on Redwood {
name
height
}
... on Ginkgo {
name
medicalUse
}
... on Oak {
name
acornType
}
}
}
Redwood will automatically detect your union types in your sdl files and resolve which of your union's types is being returned. If the returned object does not match any of the valid types, the associated operation will produce a GraphQL error.
GraphQL Handler Setup
Redwood's GraphQLHandlerOptions allows you to configure your GraphQL handler schema, context, authentication, security and more.
export interface GraphQLHandlerOptions {
/**
* @description The identifier used in the GraphQL health check response.
* It verifies readiness when sent as a header in the readiness check request.
*
* By default, the identifier is `yoga` as seen in the HTTP response header `x-yoga-id: yoga`
*/
healthCheckId?: string
/**
* @description Customize GraphQL Logger
*
* Collect resolver timings, and exposes trace data for
* an individual request under extensions as part of the GraphQL response.
*/
loggerConfig: LoggerConfig
/**
* @description Modify the resolver and global context.
*/
context?: Context | ContextFunction
/**
* @description An async function that maps the auth token retrieved from the
* request headers to an object.
* Is it executed when the `auth-provider` contains one of the supported
* providers.
*/
getCurrentUser?: GetCurrentUser
/**
* @description A callback when an unhandled exception occurs. Use this to disconnect your prisma instance.
*/
onException?: () => void
/**
* @description Services passed from the glob import:
* import services from 'src/services\/**\/*.{js,ts}'
*/
services: ServicesGlobImports
/**
* @description SDLs (schema definitions) passed from the glob import:
* import sdls from 'src/graphql\/**\/*.{js,ts}'
*/
sdls: SdlGlobImports
/**
* @description Directives passed from the glob import:
* import directives from 'src/directives/**\/*.{js,ts}'
*/
directives?: DirectiveGlobImports
/**
* @description A list of options passed to [makeExecutableSchema]
* (https://www.graphql-tools.com/docs/generate-schema/#makeexecutableschemaoptions).
*/
schemaOptions?: Partial<IExecutableSchemaDefinition>
/**
* @description CORS configuration
*/
cors?: CorsConfig
/**
* @description Customize GraphQL Armor plugin configuration
*
* @see https://escape-technologies.github.io/graphql-armor/docs/configuration/examples
*/
armorConfig?: ArmorConfig
/**
* @description Customize the default error message used to mask errors.
*
* By default, the masked error message is "Something went wrong"
*
* @see https://github.com/dotansimha/envelop/blob/main/packages/core/docs/use-masked-errors.md
*/
defaultError?: string
/**
* @description Only allows the specified operation types (e.g. subscription, query or mutation).
*
* By default, only allow query and mutation (ie, do not allow subscriptions).
*
* An array of GraphQL's OperationTypeNode enums:
* - OperationTypeNode.SUBSCRIPTION
* - OperationTypeNode.QUERY
* - OperationTypeNode.MUTATION
*
* @see https://github.com/dotansimha/envelop/tree/main/packages/plugins/filter-operation-type
*/
allowedOperations?: AllowedOperations
/**
* @description Custom Envelop plugins
*/
extraPlugins?: Plugin[]
/**
* @description Auth-provider specific token decoder
*/
authDecoder?: Decoder
/**
* @description Customize the GraphiQL Endpoint that appears in the location bar of the GraphQL Playground
*
* Defaults to '/graphql' as this value must match the name of the `graphql` function on the api-side.
*/
graphiQLEndpoint?: string
/**
* @description Function that returns custom headers (as string) for GraphiQL.
*
* Headers must set auth-provider, Authorization and (if using dbAuth) the encrypted cookie.
*/
generateGraphiQLHeader?: GenerateGraphiQLHeader
}
Directive Setup
Redwood makes it easy to code, organize, and map your directives into the GraphQL schema.
You simply add them to the directives directory and the createGraphQLHandler will do all the work.
import { createGraphQLHandler } from '@redwoodjs/graphql-server'
import directives from 'src/directives/**/*.{js,ts}' // 👈 directives live here
import sdls from 'src/graphql/**/*.sdl.{js,ts}'
import services from 'src/services/**/*.{js,ts}'
import { db } from 'src/lib/db'
import { logger } from 'src/lib/logger'
export const handler = createGraphQLHandler({
loggerConfig: { logger, options: {} },
armorConfig, // 👈 custom GraphQL Security configuration
directives, // 👈 directives are added to the schema here
sdls,
services,
onException: () => {
// Disconnect from your database with an unhandled exception.
db.$disconnect()
},
})
Note: Check-out the in-depth look at Redwood Directives that explains how to generate directives so you may use them to validate access and transform the response.
Logging Setup
For a details on setting up GraphQL Logging, see Logging.
Security Setup
For a details on setting up GraphQL Security, see Security.
Logging
Logging is essential in production apps to be alerted about critical errors and to be able to respond effectively to support issues. In staging and development environments, logging helps you debug queries, resolvers and cell requests.
We want to make logging simple when using RedwoodJS and therefore have configured the api-side GraphQL handler to log common information about your queries and mutations. Log statements also be optionally enriched with operation names, user agents, request ids, and performance timings to give you more visibility into your GraphQL api.
By configuring the GraphQL handler to use your api side RedwoodJS logger, any errors and other log statements about the GraphQL execution will be logged to the destination you've set up: to standard output, file, or transport stream.
You configure the logger using the loggerConfig that accepts a logger and a set of GraphQL Logger Options.
Configure the GraphQL Logger
A typical GraphQLHandler graphql.ts is as follows:
// ...
import { logger } from 'src/lib/logger'
// ...
export const handler = createGraphQLHandler({
loggerConfig: { logger, options: {} },
// ...
})
Log Common Information
The loggerConfig takes several options that logs meaningful information along the graphQL execution lifecycle.
| Option | Description |
|---|---|
| data | Include response data sent to client. |
| operationName | Include operation name. The operation name is a meaningful and explicit name for your operation. It is only required in multi-operation documents, but its use is encouraged because it is very helpful for debugging and server-side logging. When something goes wrong (you see errors either in your network logs, or in the logs of your GraphQL server) it is easier to identify a query in your codebase by name instead of trying to decipher the contents. Think of this just like a function name in your favorite programming language. See https://graphql.org/learn/queries/#operation-name |
| requestId | Include the event's requestId, or if none, generate a uuid as an identifier. |
| query | Include the query. This is the query or mutation (with fields) made in the request. |
| tracing | Include the tracing and timing information. This will log various performance timings within the GraphQL event lifecycle (parsing, validating, executing, etc). |
| userAgent | Include the browser (or client's) user agent. This can be helpful to know what type of client made the request to resolve issues when encountering errors or unexpected behavior. |
Therefore, if you wish to log the GraphQL query made, the data returned, and the operationName used, you would
export const handler = createGraphQLHandler({
loggerConfig: {
logger,
options: { data: true, operationName: true, query: true },
},
// ...
})
Exclude Operations
You can exclude GraphQL operations by name with excludeOperations.
This is useful when you want to filter out certain operations from the log output, for example, IntrospectionQuery from GraphQL playground:
export const handler = createGraphQLHandler({
loggerConfig: {
logger,
options: { excludeOperations: ['IntrospectionQuery'] },
},
directives,
sdls,
services,
onException: () => {
// Disconnect from your database with an unhandled exception.
db.$disconnect()
},
})
Relevant anatomy of an operation
In the example below,
"FilteredQuery"is the operation's name. That's what you'd pass toexcludeOperationsif you wanted it filtered out.export const filteredQuery = `
query FilteredQuery {
me {
id
name
}
}
Benefits of Logging
Benefits of logging common GraphQL request information include debugging, profiling, and resolving issue reports.
Operation Name Identifies Cells
The operation name is a meaningful and explicit name for your operation. It is only required in multi-operation documents, but its use is encouraged because it is very helpful for debugging and server-side logging.
Because your cell typically has a unique operation name, logging this can help you identify which cell made a request.
// ...
export const handler = createGraphQLHandler({
loggerConfig: { logger, options: { operationName: true } },
// ...
RequestId for Support Issue Resolution
Often times, your deployment provider will provide a request identifier to help reconcile and track down problems at an infrastructure level. For example, AWS API Gateway and AWS Lambda (used by Netlify, for example) provides requestId on the event.
You can include the request identifier setting the requestId logger option to true.
// ...
export const handler = createGraphQLHandler({
loggerConfig: { logger, options: { requestId: true } },
// ...
And then, when working to resolve a support issue with your deployment provider, you can supply this request id to help them track down and investigate the problem more easily.
No Need to Log within Services
By configuring your GraphQL logger to include data and query information about each request you can keep your service implementation clean, concise and free of repeated logger statements in every resolver -- and still log the useful debugging information.
// ...
export const handler = createGraphQLHandler({
loggerConfig: { logger, options: { data: true, operationName: true, query: true } },
// ...
// api/src/services/posts.js
//...
export const post = async ({ id }) => {
return await db.post.findUnique({
where: { id },
})
}
//...
The GraphQL handler will then take care of logging your query and data -- as long as your logger is setup to log at the info level and above.
You can also disable the statements in production by just logging at the
warnlevel or above
This means that you can keep your services free of logger statements, but still see what's happening!
api | POST /graphql 200 7.754 ms - 1772
api | DEBUG [2021-09-29 16:04:09.313 +0000] (graphql-server): GraphQL execution started: BlogPostQuery
api | operationName: "BlogPostQuery"
api | query: {
api | "id": 3
api | }
api | DEBUG [2021-09-29 16:04:09.321 +0000] (graphql-server): GraphQL execution completed: BlogPostQuery
api | data: {
api | "post": {
api | "id": 3,
api | "body": "Meh waistcoat succulents umami asymmetrical, hoodie post-ironic paleo chillwave tote bag. Trust fund kitsch waistcoat vape, cray offal gochujang food truck cloud bread enamel pin forage. Roof party chambray ugh occupy fam stumptown. Dreamcatcher tousled snackwave, typewriter lyft unicorn pabst portland blue bottle locavore squid PBR&B tattooed.",
api | "createdAt": "2021-09-24T16:51:06.198Z",
api | "__typename": "Post"
api | }
api | }
api | operationName: "BlogPostQuery"
api | query: {
api | "id": 3
api | }
api | POST /graphql 200 9.386 ms - 441
Send to Third-party Transports
Stream to third-party log and application monitoring services vital to production logging in serverless environments like logFlare, Datadog or LogDNA
Supports Log Redaction
Everyone has heard of reports that Company X logged emails, or passwords to files or systems that may not have been secured. While RedwoodJS logging won't necessarily prevent that, it does provide you with the mechanism to ensure that won't happen.
To redact sensitive information, you can supply paths to keys that hold sensitive data using the RedwoodJS logger redact option.
Because this logger is used with the GraphQL handler, it will respect any redaction paths setup.
For example, you have chosen to log data return by each request, then you may want to redact sensitive information, like email addresses from your logs.
Here is an example of an application /api/src/lib/logger.ts configured to redact email addresses. Take note of the path data.users[*].email as this says, in the data attribute, redact the email from every user:
import { createLogger, redactionsList } from '@redwoodjs/api/logger'
export const logger = createLogger({
options: {
redact: [...redactionsList, 'email', 'data.users[*].email'],
},
})
Timing Traces and Metrics
Often you want to measure and report how long your queries take to execute and respond. You may already be measuring these durations at the database level, but you can also measure the time it takes for your the GraphQL server to parse, validate, and execute the request.
You may turn on logging these metrics via the tracing GraphQL configuration option.
// ...
export const handler = createGraphQLHandler({
loggerConfig: { logger, options: { tracing: true } },
// ...
Let's say we wanted to get some benchmark numbers for the "find post by id" resolver
return await db.post.findUnique({
where: { id },
})
We see that this request took about 500 msecs (note: duration is reported in nanoseconds).
For more details about the information logged and its format, see Apollo Tracing.
pi | INFO [2021-07-09 14:25:52.452 +0000] (graphql-server): GraphQL willSendResponse
api | tracing: {
api | "version": 1,
api | "startTime": "2021-07-09T14:25:51.931Z",
api | "endTime": "2021-07-09T14:25:52.452Z",
api | "duration": 521131526,
api | "execution": {
api | "resolvers": [
api | {
api | "path": [
api | "post"
api | ],
api | "parentType": "Query",
api | "fieldName": "post",
api | "returnType": "Post!",
api | "startOffset": 1787428,
api | "duration": 519121497
api | },
api | {
api | "path": [
api | "post",
api | "id"
api | ],
api | "parentType": "Post",
api | "fieldName": "id",
api | "returnType": "Int!",
api | "startOffset": 520982888,
api | "duration": 25140
api | },
... more paths follow ...
api | ]
api | }
api | }
By logging the operation name and extracting the duration for each query, you can easily collect and benchmark query performance.
Security
Parsing a GraphQL operation document is a very expensive and compute intensive operation that blocks the JavaScript event loop. If an attacker sends a very complex operation document with slight variations over and over again he can easily degrade the performance of the GraphQL server.
RedwoodJS will by default reject a variety malicious operation documents; that is, it'll prevent attackers from making malicious queries or mutations.
RedwoodJS is configured out-of-the-box with GraphQL security best practices:
- Schema Directive-based Authentication including RBAC validation
- Production Deploys disable Introspection and GraphQL Playground automatically
- Reject Malicious Operation Documents (Max Aliases, Max Cost, Max Depth, Max Directives, Max Tokens)
- Prevent Information Leaks (Block Field Suggestions, Mask Errors)
And with the Yoga Envelop Plugin ecosystem available to you, there are options for:
- CSRF Protection
- Rate Limiting
- and more.
Authentication
By default, your GraphQL endpoint is open to the world.
That means anyone can request any query and invoke any Mutation. Whatever types and fields are defined in your SDL is data that anyone can access.
Redwood encourages being secure by default by defaulting all queries and mutations to have the @requireAuth directive when generating SDL or a service.
When your app builds and your server starts up, Redwood checks that all queries and mutations have @requireAuth, @skipAuth or a custom directive applied.
If not, then your build will fail:
✖ Verifying graphql schema...
Building API...
Cleaning Web...
Building Web...
Prerendering Web...
You must specify one of @requireAuth, @skipAuth or a custom directive for
- contacts Query
- posts Query
- post Query
- updatePost Mutation
- deletePost Mutation
or your server won't startup and you should see that "Schema validation failed":
gen | Generating TypeScript definitions and GraphQL schemas...
gen | 47 files generated
api | Building... Took 593 ms
api | [GQL Server Error] - Schema validation failed
api | ----------------------------------------
api | You must specify one of @requireAuth, @skipAuth or a custom directive for
api | - posts Query
api | - createPost Mutation
api | - updatePost Mutation
api | - deletePost Mutation
To correct, just add the appropriate directive to your queries and mutations.
If not, then your build will fail and your server won't startup.
@requireAuth
To enforce authentication, simply add the @requireAuth directive in your GraphQL schema for any query or field you want protected.
It's your responsibility to implement the requireAuth() function in your app's api/src/lib/auth.{js|ts} to check if the user is properly authenticated and/or has the expected role membership.
The @requireAuth directive will call the requireAuth() function to determine if the user is authenticated or not.
Here we enforce that a user must be logged in to create. update or delete a Post.
type Post {
id: Int!
title: String!
body: String!
authorId: Int!
author: User!
createdAt: DateTime!
}
input CreatePostInput {
title: String!
body: String!
authorId: Int!
}
input UpdatePostInput {
title: String
body: String
authorId: Int
}
type Mutation {
createPost(input: CreatePostInput!): Post! @requireAuth
updatePost(id: Int!, input: UpdatePostInput!): Post! @requireAuth
deletePost(id: Int!): Post! @requireAuth
}
It's your responsibility to implement the requireAuth() function in your app's api/src/lib/auth.{js|ts} to check if the user is properly authenticated and/or has the expected role membership.
The @requireAuth directive will call the requireAuth() function to determine if the user is authenticated or not.
// ...
export const isAuthenticated = (): boolean => {
return true // 👈 replace with the appropriate check
}
// ...
export const requireAuth = ({ roles }: { roles: AllowedRoles }) => {
if (isAuthenticated()) {
throw new AuthenticationError("You don't have permission to do that.")
}
if (!hasRole({ roles })) {
throw new ForbiddenError("You don't have access to do that.")
}
}
Note: The
auth.tsfile here is the stub for a new RedwoodJS app. Once you have setup auth with your provider, this will enforce a proper authentication check.
Field-level Auth
You can apply the @requireAuth to any field as well (not just queries or mutations):
type Post {
id: Int!
title: String!
body: String! @requireAuth
authorId: Int!
author: User!
createdAt: DateTime!
}
Role-based Access Control
The @requireAuth directive lets you define roles that are permitted to perform the operation:
type Mutation {
createPost(input: CreatePostInput!): Post! @requireAuth(roles: ['AUTHOR', 'EDITOR'])
updatePost(id: Int!, input: UpdatePostInput!): Post! @@requireAuth(roles: ['EDITOR']
deletePost(id: Int!): Post! @requireAuth(roles: ['ADMIN']
}
@skipAuth
If, however, you want your query or mutation to be public, then simply use @skipAuth.
In the example, fetching all posts or a single post is allowed for all users, authenticated or not.
type Post {
id: Int!
title: String!
body: String!
authorId: Int!
author: User!
createdAt: DateTime!
}
type Query {
posts: [Post!]! @skipAuth
post(id: Int!): Post @skipAuth
}
Introspection and Playground Disabled in Production
Because it is often useful to ask a GraphQL schema for information about what queries it supports, GraphQL allows us to do so using the introspection system.
The GraphQL Playground is a way for you to interact with your schema and try out queries and mutations. It can show you the schema by inspecting it. You can find the GraphQL Playground at http://localhost:8911/graphql when your dev server is running.
Because both introspection and the playground share possibly sensitive information about your data model, your data, your queries and mutations, best practices for deploying a GraphQL Server call to disable these in production, RedwoodJS , by default, only enables introspection and the playground when running in development. That is when
process.env.NODE_ENV === 'development'.
However, there may be cases where you want to enable introspection. You can enable introspection by setting the allowIntrospection option to true.
Here is an example of createGraphQLHandler function with the allowIntrospection option set to true:
export const handler = createGraphQLHandler({
authDecoder,
getCurrentUser,
loggerConfig: { logger, options: {} },
directives,
sdls,
services,
allowIntrospection: true, // 👈 enable introspection in all environments
onException: () => {
// Disconnect from your database with an unhandled exception.
db.$disconnect()
},
})
Enabling introspection in production may pose a security risk, as it allows users to access information about your schema, queries, and mutations. Use this option with caution and make sure to secure your GraphQL API properly.
GraphQL Armor Configuration
GraphQL Armor is a middleware that adds a security layer the RedwoodJS GraphQL endpoint configured with sensible defaults.
You don't have to configure anything to enforce protection against alias, cost, depth, directive, tokens abuse in GraphQL operations as well as to block field suggestions or revealing error messages that might leak sensitive information.
But, if you need to enable, disable to modify the default settings, GraphQL Armor is fully configurable in a per-plugin fashion.
Simply define and provide a custom GraphQL Security configuration to your createGraphQLHandler:
export const handler = createGraphQLHandler({
authDecoder,
getCurrentUser,
loggerConfig: { logger, options: {} },
directives,
sdls,
services,
armorConfig, // 👈 custom GraphQL Security configuration
onException: () => {
// Disconnect from your database with an unhandled exception.
db.$disconnect()
},
})
For example, the default max query depth limit is 6. To change that setting to 2 levels, simply provide the configuration to your handler:
export const handler = createGraphQLHandler({
authDecoder,
getCurrentUser,
loggerConfig: { logger, options: {} },
directives,
sdls,
services,
armorConfig: { maxDepth: { n: 2 } },
onException: () => {
// Disconnect from your database with an unhandled exception.
db.$disconnect()
},
})
Max Aliases
This protection is enabled by default.
Limit the number of aliases in a document. Defaults to 15.
Example
Aliases allow you to rename the data that is returned in a query’s results. They manipulate the structure of the query result that is fetched from your service, displaying it according to your web component's needs.
This contrived example uses 11 alias to rename a Post's id and title to various permutations of post, article, and blog to return a different shape in the query result as articles:
{
articles: posts {
id
articleId: id
postId: id
articlePostId: id
postArticleId: id
blogId: id
title
articleTitle: title
postTitle: title
articlePostTitle: title
postArticleTitle: title
blogTitle: title
}
}
Configuration and Defaults
Limit the number of aliases in a document. Defaults to 15.
You can change the default value via the maxAliases setting when creating your GraphQL handler.
{
maxAliases: {
enabled: true,
n: 15,
}
}
Cost Limit
This protection is enabled by default.
It analyzes incoming GraphQL queries and applies a cost analysis algorithm to prevent resource overload by blocking too expensive requests (DoS attack attempts).
The cost computation is quite simple (and naive) at the moment but there are plans to make it evolve toward a extensive plugin with many features.
Defaults to a overall maxCost limit of 5000.
Overview
Cost is a factor of the kind of field and depth. Total Cost is a cumulative sum of each field based on its type and its depth in the query.
Scalar fields -- those that return values like strings or numbers -- are worth one value; whereas are objects are worth another.
How deep they are nested in the query is a multiplier factor such that:
COST = FIELD_KIND_COST * (DEPTH * DEPTH_COST_FACTOR)
TOTAL_COST = SUM(COST)
If the TOTAL_COST exceeds the maxCost, an error stops GraphQL execution and rejects the request.
You have control over the field kind and depth costs settings, but the defaults are:
objectCost: 2, // cost of retrieving an object
scalarCost: 1, // cost of retrieving a scalar
depthCostFactor: 1.5, // multiplicative cost of depth
Example
In this small example, we have one object field me that contains two, nested scalar fields id and me. There is an operation profile (which is neither a scalar nor object and thus ignored as part of the cost calculation).
{
profile {
me {
id
user
}
}
}
The cost breakdown for cost is:
- two scalars
idanduserworth 1 each - they are at level 1 depth with a depth factor of 1.5
- 2 * ( 1 * 1.5 ) = 2 * 1.5 = 3
- their parent object is
meworth 2
Therefore the total cost is 2 + 3 = 5.
The operation definition query of profile is ignored in the calculation. This is the case even if you name your query MY_PROFILE like:
{
profile MY_PROFILE {
me {
id
user
}
}
}
Configuration and Defaults
Defaults to a overall maxCost limit of 5000.
You can change the default value via the costLimit setting when creating your GraphQL handler.
{
costLimit: {
enabled: true,
maxCost: 5000, // maximum cost of a request before it is rejected
objectCost: 2, // cost of retrieving an object
scalarCost: 1, // cost of retrieving a scalar
depthCostFactor: 1.5, // multiplicative cost of depth
}
}
Max Depth Limit
This protection is enabled by default.
Limit the depth of a document. Defaults to 6 levels.
Attackers often submit expensive, nested queries to abuse query depth that could overload your database or expend costly resources.
Typically, these types of unbounded, complex and expensive GraphQL queries are usually huge deeply nested and take advantage of an understanding of your schema (hence why schema introspection is disabled by default in production) and the data model relationships to create "cyclical" queries.
Example
An example of a cyclical query here takes advantage of knowing that an author has posts and each post has an author ... that has posts ... that has an another that ... etc.
This cyclical query has a depth of 8.
// cyclical query example
// depth: 8+
query cyclical {
author(id: 'jules-verne') {
posts {
author {
posts {
author {
posts {
author {
... {
... # more deep nesting!
}
}
}
}
}
}
}
}
}
Configuration and Defaults
Defaults to 6 levels.
You can change the default value via the maxDepth setting when creating your GraphQL handler.
{
maxDepth: {
enabled: true,
n: 6,
}
}
Max Directives
This protections is enabled by default.
Limit the number of directives in a document. Defaults to 50.
Example
The following example demonstrates that by using the @include and @skip GraphQL query directives one can design a large request that requires computation, but in fact returns the expected response ...
{
posts {
id @include(if:true)
id @include(if:false)
id @include(if:false)
id @skip(if:true)
id @skip(if:true)
id @skip(if:true))
title @include(if:true)
title @include(if:false)
title @include(if:false)
title @skip(if:true)
title @skip(if:true)
title @skip(if:true)
}
}
... of formatted Posts with just a single id and title.
{
"data": {
"posts": [
{
"id": 1,
"title": "A little more about RedwoodJS"
},
{
"id": 2,
"title": "What is GraphQL?"
},
{
"id": 3,
"title": "Welcome to the RedwoodJS Community!"
},
{
"id": 4,
"title": "10 ways to secure your GraphQL endpoint"
}
]
}
}
By limiting the maximum number of directives in the document, malicious queries can be rejected.
Configuration and Defaults
You can change the default value via the maxDirectives setting when creating your GraphQL handler.
{
maxDirectives: {
enabled: true,
n: 50,
}
}
Max Tokens
This protection is enabled by default.
Limit the number of GraphQL tokens in a document.
In computer science, lexical analysis, lexing or tokenization is the process of converting a sequence of characters into a sequence of lexical tokens.
E.g. given the following GraphQL operation.
graphql {
me {
id
user
}
}
The tokens are query, {, me, {, id, user, } and }. Having a total count of 8 tokens.
Example
Given the query with 8 tokens:
graphql {
me {
id
user
}
}
And a custom configuration to all a maximum of two tokens:
const armorConfig = {
maxTokens: { n: 2 },
}
An error is raised:
'Syntax Error: Token limit of 2 exceeded, found 3.'
When reporting the number of found tokens, then number found is not the total tokens, but the value when found that exceeded the limit.
Therefore found would be n + 1.
Configuration and Defaults
Defaults to 1000.
You can change the default value via the maxTokens setting when creating your GraphQL handler.
{
maxTokens: {
enabled: true,
n: 1000,
}
}
Block Field Suggestions
This plugin is enabled by default.
It will prevent suggesting fields in case of an erroneous request. Suggestions can lead to the leak of your schema even with disabled introspection, which can be very detrimental in case of a private API.
Example of such a suggestion:
Cannot query field "sta" on type "Media". Did you mean "stats", "staff", or "status"?
Example
Configuration and Defaults
Enabled by default.
You can change the default value via the blockFieldSuggestions setting when creating your GraphQL handler.
{
blockFieldSuggestion: {
enabled: true,
}
}
Enabling will hide the field suggestion:
Cannot query field "sta" on type "Media". [Suggestion hidden]?
Orm if you want a custom mask:
{
blockFieldSuggestion: {
mask: '<REDACTED>'
},
}
`Cannot query field "sta" on type "Media". [REDACTED]?
Error Masking
In many GraphQL servers, when an error is thrown, the details of that error are leaked to the outside world. The error and its message are then returned in the response and a client might reveal those errors in logs or even render the message to the user. You could potentially leak sensitive or other information about your app you don't want to share—such as database connection failures or even the presence of certain fields.
Redwood is here to help!
Redwood prevents leaking sensitive error-stack information out-of-the-box for unexpected errors. If an error that isn't one of Redwood's GraphQL Errors or isn't based on a GraphQLError is thrown:
- The original error and its message will be logged using the defined GraphQL logger, so you'll know what went wrong
- A default message "Something went wrong" will replace the error message in the response (Note: you can customize this message)
Customizing the Error Message
But what if you still want to share an error message with client? Simply use one of Redwood's GraphQL Errors and your custom message will be shared with your users.
Customizing the Default Error Message
You can customize the default "Something went wrong" message used when the error is masked via the defaultError setting on the createGraphQLHandler:
export const handler = createGraphQLHandler({
loggerConfig: { logger, options: {} },
directives,
sdls,
services,
defaultError: 'Sorry about that', // 👈 Customize the error message
onException: () => {
// Disconnect from your database with an unhandled exception.
db.$disconnect()
},
})
Redwood Errors
Redwood Errors are inspired from Apollo Server Error codes for common use cases:
To use a Redwood Error, import each from @redwoodjs/graphql-server.
SyntaxError- An unspecified error occurredValidationError- Invalid input to a serviceAuthenticationError- Failed to authenticateForbiddenError- Unauthorized to accessUserInputError- Missing input to a service
If you use one of the errors, then the message provided will not be masked and will be shared in the GraphQL response:
import { UserInputError } from '@redwoodjs/graphql-server'
// ...
throw new UserInputError('An email is required.')
then the message provided will not be masked and it will be shred in the GraphQL response.
Custom Errors and Uses
Need you own custom error and message?
Maybe you're integrating with a third-party api and want to handle errors from that service and also want control of how that error is shared with your user client-side.
Simply extend from RedwoodError and you're all set!
export class MyCustomError extends RedwoodError {
constructor(message: string, extensions?: Record<string, any>) {
super(message, extensions)
}
}
For example, in your service, you can create and use it to handle the error and return a friendly message:
export class WeatherError extends RedwoodError {
constructor(message: string, extensions?: Record<string, any>) {
super(message, extensions)
}
}
export const getWeather = async ({ input }: WeatherInput) {
try {
const weather = weatherClient.get(input.zipCode)
} catch(error) {
// rate limit issue
if (error.statusCode = 429) {
throw new WeatherError('Unable to get the latest weather updates at the moment. Please try again shortly.')
}
// other error
throw new WeatherError(`We could not get the weather for ${input.zipCode}.`)
}
}
CSRF Prevention
If you have CORS enabled, almost all requests coming from the browser will have a preflight request - however, some requests are deemed "simple" and don't make a preflight. One example of such a request is a good ol' GET request without any headers, this request can be marked as "simple" and have preflight CORS checks skipped therefore skipping the CORS check.
This attack can be mitigated by saying: "all GET requests must have a custom header set". This would force all clients to manipulate the headers of GET requests, marking them as "_not-_simple" and therefore always executing a preflight request.
You can achieve this by using the @graphql-yoga/plugin-csrf-prevention GraphQL Yoga plugin.
Self-Documenting GraphQL API
RedwoodJS helps you document your GraphQL API by generating commented SDL used for GraphiQL and the GraphQL Playground explorer -- as well as can be turned into API docs using tools like Docusaurus.
If you specify the SDL generator with its --docs option, any comments (which the GraphQL spec calls "descriptions") will be incorporated into your RedwoodJS app's graphql.schema file when generating types.
If you comment your Prisma schema models, its fields, or enums, the SDL generator will use those comments as the documentation.
If there is no Prisma comment, then the SDL generator will default a comment that you can then edit.
If you re-generate the SDL, any custom comments will be overwritten. However, if you make those edits in your Prisma schema, then those will be used.
Prisma Schema Comments
Your Prisma schema is documented with triple slash comments (///) that precedes:
- Model names
- Enum names
- each Model field name
/// A blog post.
model Post {
/// The unique identifier of a post.
id Int @id @default(autoincrement())
/// The title of a post.
title String
/// The content of a post.
body String
/// When the post was created.
createdAt DateTime @default(now())
}
/// A list of allowed colors.
enum Color {
RED
GREEN
BLUE
}
SDL Comments
When used with --docs option, SDL generator adds comments for:
- Directives
- Queries
- Mutations
- Input Types
By default, the --docs option to the SDL generator is false and comments are not created.
Comments [enclosed in """ or "](GraphQL spec in your sdl files will be included in the generated GraphQL schema at the root of your project (.redwood/schema.graphql).
"""
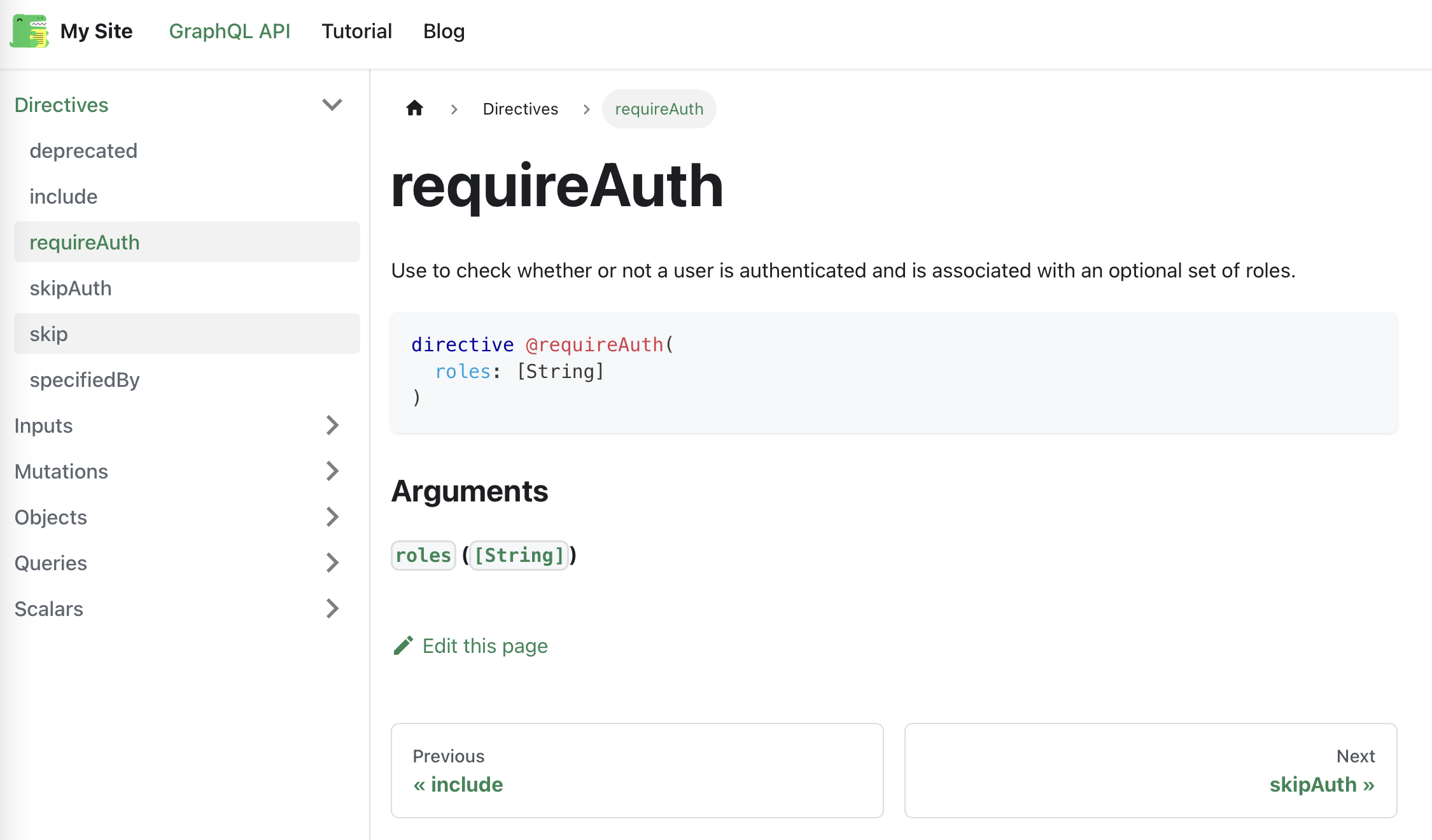
Use to check whether or not a user is authenticated and is associated
with an optional set of roles.
"""
directive @requireAuth(roles: [String]) on FIELD_DEFINITION
"""Use to skip authentication checks and allow public access."""
directive @skipAuth on FIELD_DEFINITION
"""
Autogenerated input type of InputPost.
"""
input CreatePostInput {
"The content of a post."
body: String!
"The title of a post."
title: String!
}
"""
Autogenerated input type of UpdatePost.
"""
input UpdatePostInput {
"The content of a post."
body: String
"The title of a post."
title: String
}
"""
A blog post.
"""
type Post {
"The content of a post."
body: String!
"Description for createdAt."
createdAt: DateTime!
"The unique identifier of a post."
id: Int!
"The title of a post."
title: String!
}
"""
About mutations
"""
type Mutation {
"Creates a new Post."
createPost(input: CreatePostInput!): Post!
"Deletes an existing Post."
deletePost(id: Int!): Post!
"Updates an existing Post."
updatePost(id: Int!, input: UpdatePostInput!): Post!
}
"""
About queries
"""
type Query {
"Fetch a Post by id."
post(id: Int!): Post
"Fetch Posts."
posts: [Post!]!
}
Root Schema
Documentation is also generated for the Redwood Root Schema that defines details about Redwood such as the current user and version information.
type Query {
"Fetches the Redwood root schema."
redwood: Redwood
}
"""
The Redwood Root Schema
Defines details about Redwood such as the current user and version information.
"""
type Redwood {
"The current user."
currentUser: JSON
"The version of Prisma."
prismaVersion: String
"The version of Redwood."
version: String
}
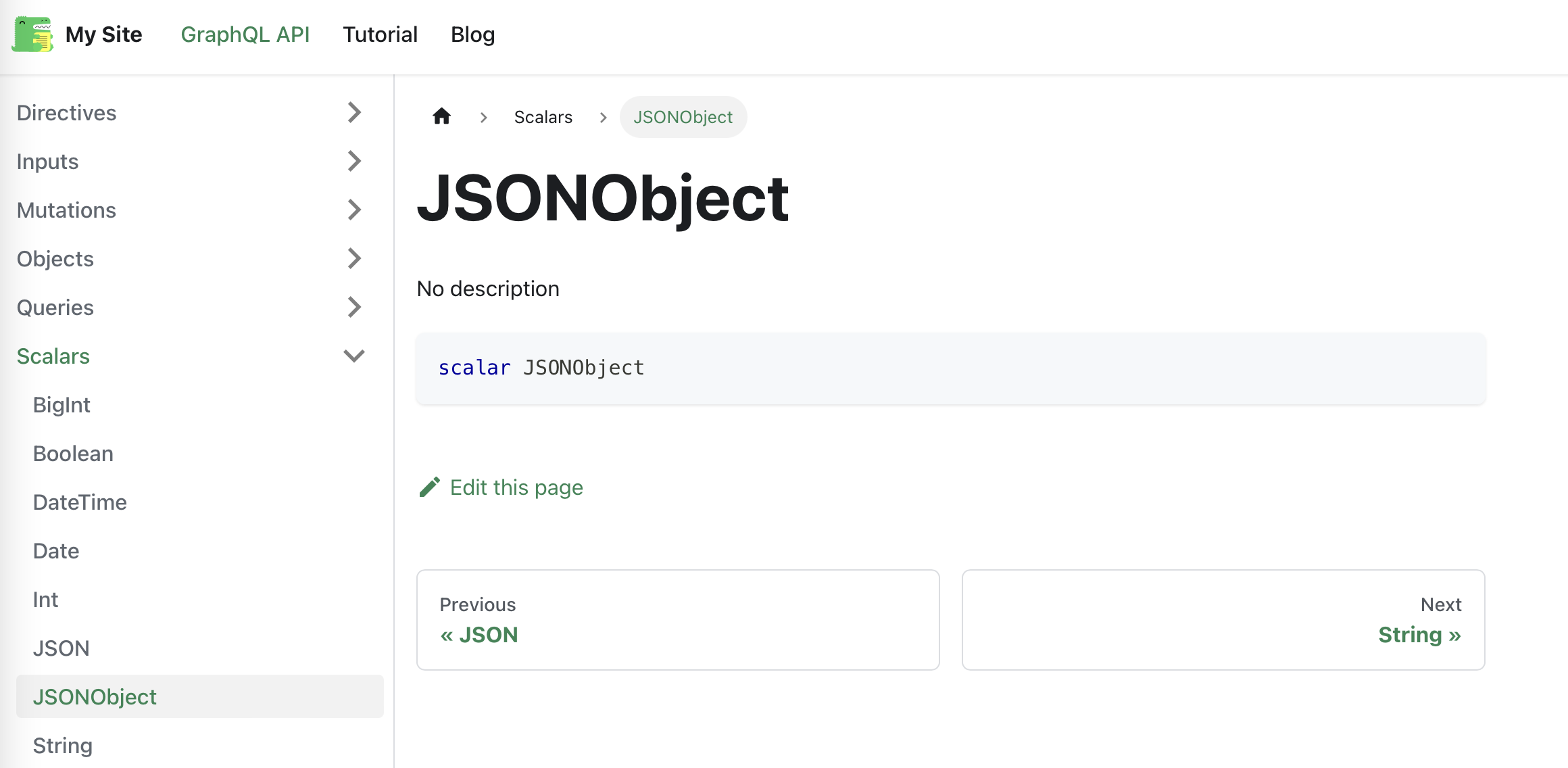
scalar BigInt
scalar Date
scalar DateTime
scalar JSON
scalar JSONObject
scalar Time
Preview in GraphiQL
The GraphQL Playground aka GraphiQL is a way for you to interact with your schema and try out queries and mutations. It can show you the schema by inspecting it. You can find the GraphQL Playground at http://localhost:8911/graphql when your dev server is running.
The documentation generated is present when exploring the schema.
Queries
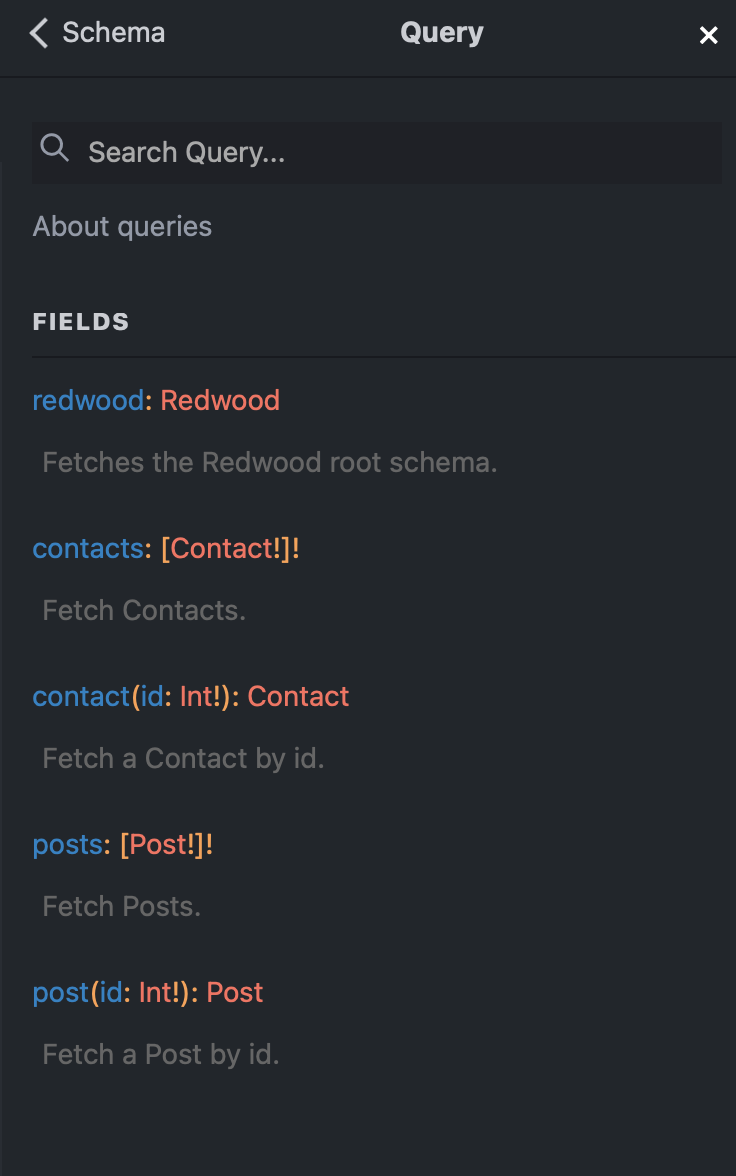
Mutations
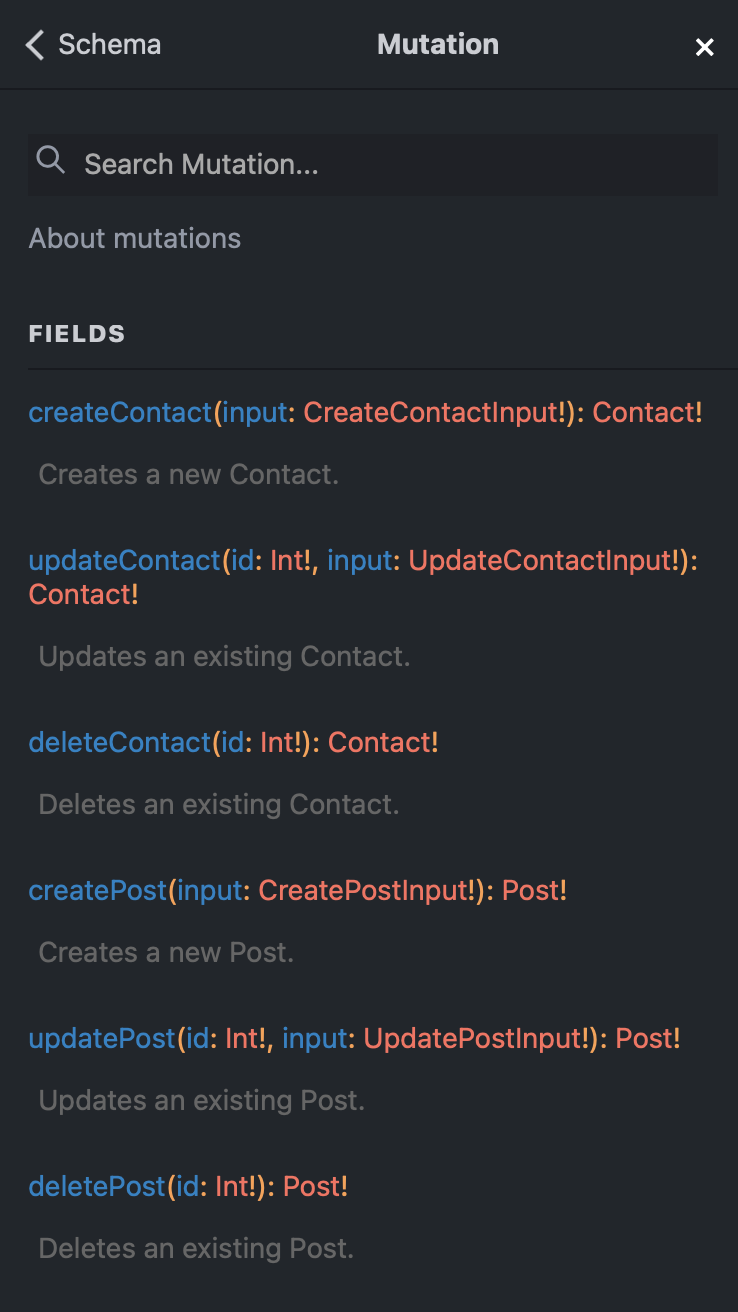
Model Types
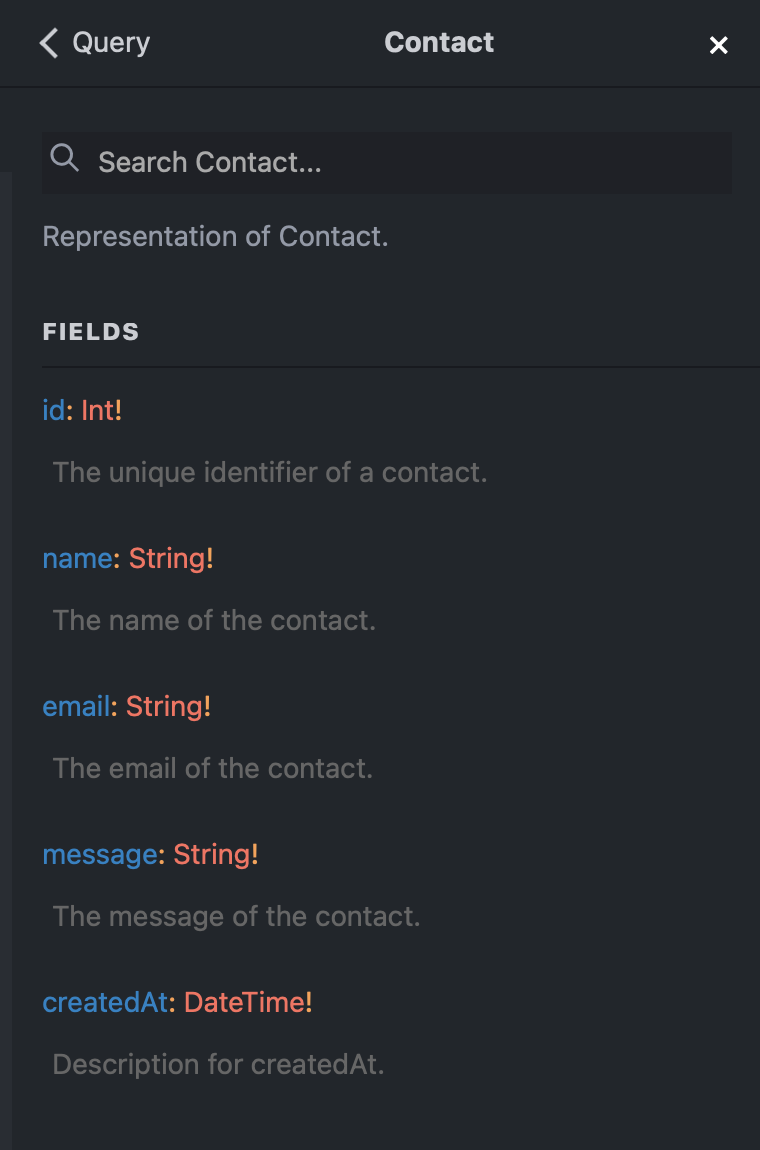
Input Types
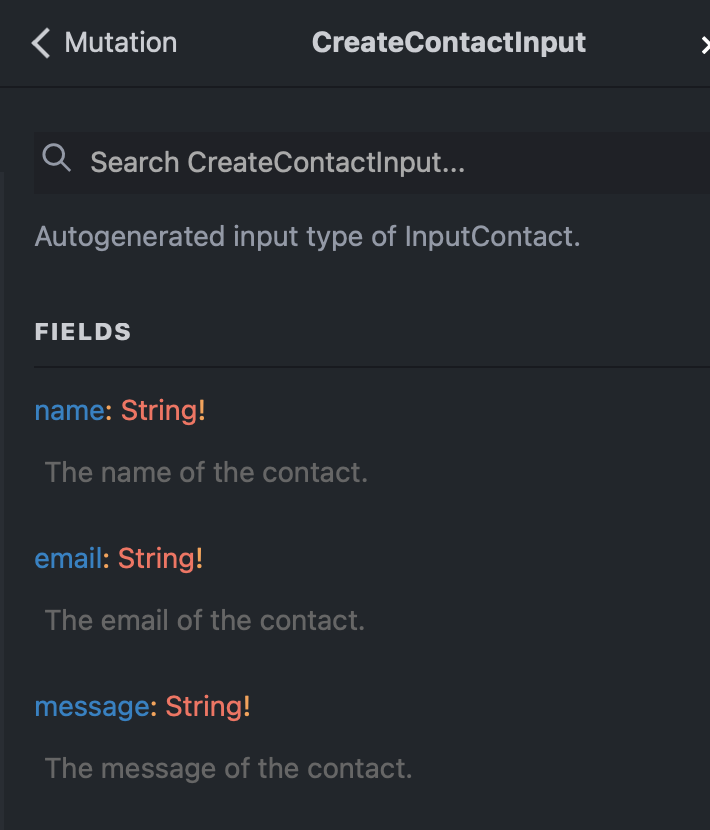
Use in Docusaurus
If your project uses Docusaurus, the generated commented SDL can be used to publish documentation using the graphql-markdown plugin.
Basic Setup
The following is some basic setup information, but please consult Docusaurus and the graphql-markdown for latest instructions.
- Install Docusaurus (if you have not done so already)
npx create-docusaurus@latest docs classic
Add docs to your workspaces in the project's package.json:
"workspaces": {
"packages": [
"docs",
"api",
"web",
"packages/*"
]
},
- Ensure a
docsdirectory exists at the root of your project
mkdir docs // if needed
- Install the GraphQL Generators Plugin
yarn workspace docs add @edno/docusaurus2-graphql-doc-generator graphql
- Ensure a Directory for your GraphQL APi generated documentation resides in with the Docusaurus directory
/docsstructure
// Change into the "docs" workspace
cd docs
// you should have the "docs" directory and within that a "graphql-api" directory
mkdir docs/graphql-api // if needed
- Update
docs/docusaurus.config.jsand configure the plugin and navbar
// docs/docusaurus.config.js
// ...
plugins: [
[
'@edno/docusaurus2-graphql-doc-generator',
{
schema: '../.redwood/schema.graphql',
rootPath: './docs',
baseURL: 'graphql-api',
linkRoot: '../..',
},
],
],
// ...
themeConfig:
/** @type {import('@docusaurus/preset-classic').ThemeConfig} */
({
navbar: {
title: 'My Site',
logo: {
alt: 'My Site Logo',
src: 'img/logo.svg',
},
items: [
{
to: '/docs/graphql-api', // adjust the location depending on your baseURL (see configuration)
label: 'GraphQL API', // change the label with yours
position: 'right',
},
//...
- Update
docs/sidebars.jsto include the generatedgraphql-api/sidebar-schema.js
// docs/sidebars.js
/**
* Creating a sidebar enables you to:
* - create an ordered group of docs
* - render a sidebar for each doc of that group
* - provide next/previous navigation
*
* The sidebars can be generated from the filesystem, or explicitly defined here.
*
* Create as many sidebars as you want.
*/
// @ts-check
/** @type {import('@docusaurus/plugin-content-docs').SidebarsConfig} */
const sidebars = {
// By default, Docusaurus generates a sidebar from the docs folder structure
tutorialSidebar: [
{
type: 'autogenerated',
dirName: '.',
},
],
...require('./docs/graphql-api/sidebar-schema.js'),
}
module.exports = sidebars
- Generate the docs
yarn docusaurus graphql-to-doc
You can overwrite the generated docs and bypass the plugin's diffMethod use --force.
`yarn docusaurus graphql-to-doc --force
- Start Docusaurus
yarn start
Example Screens
Schema Documentation
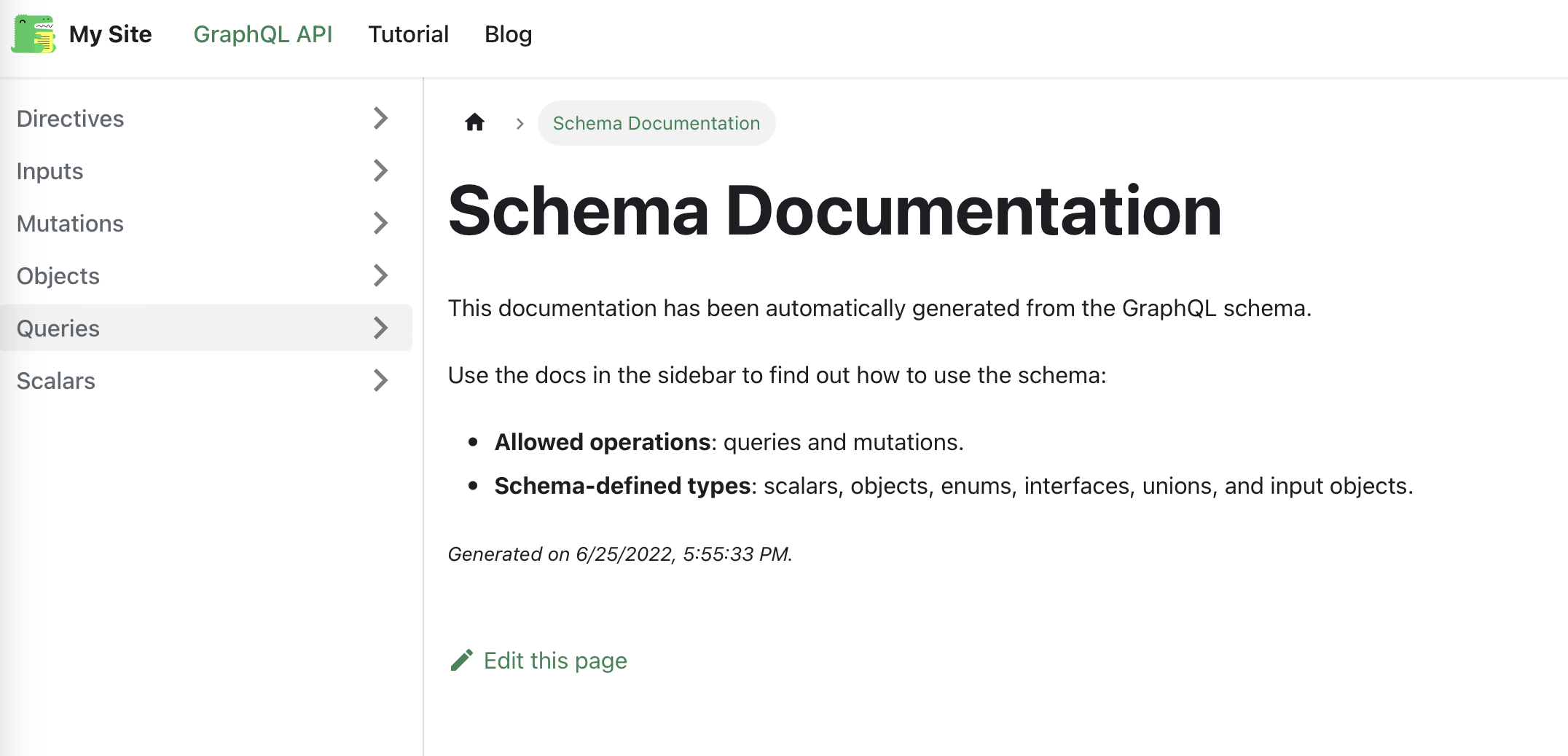
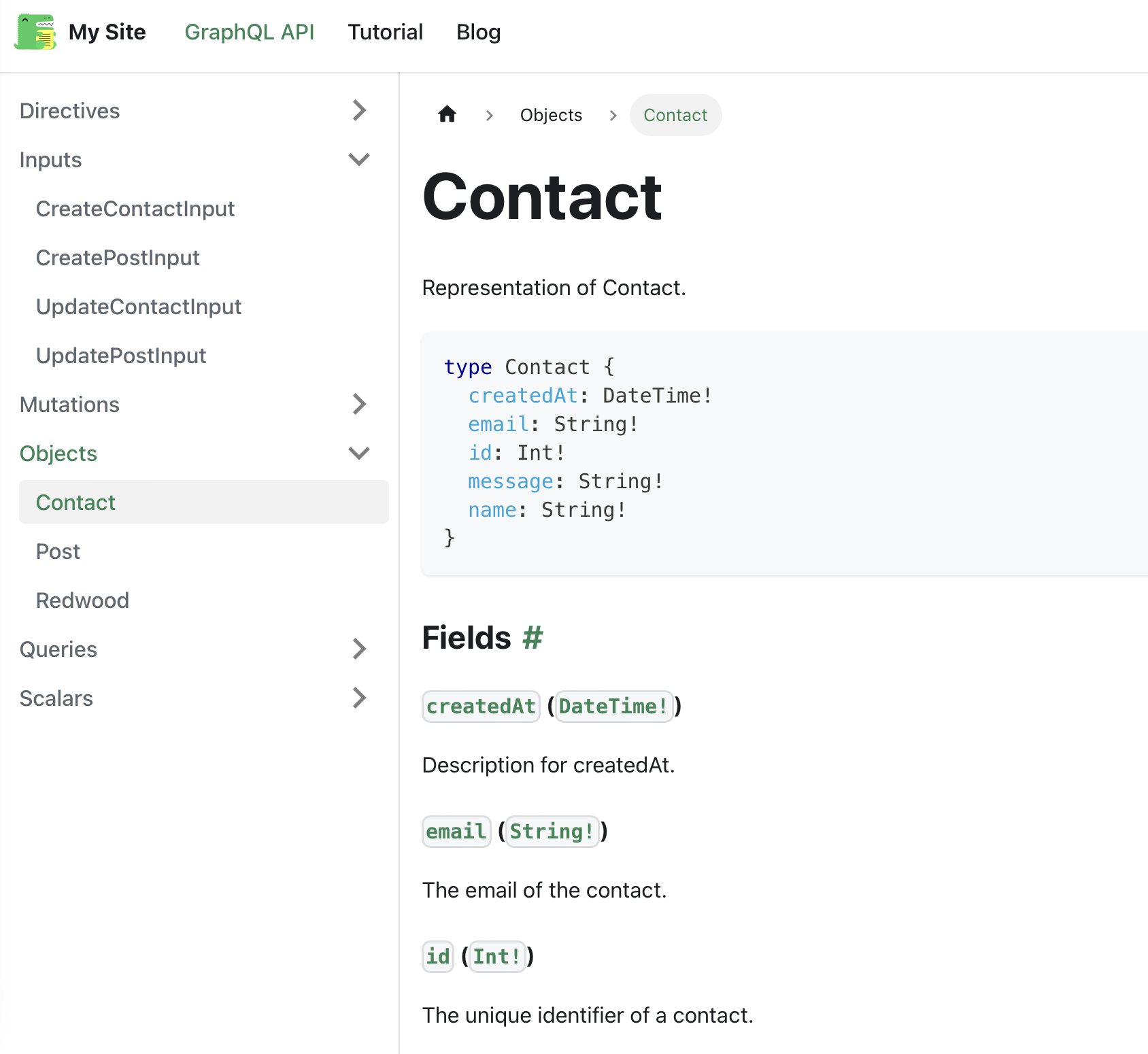
Type Example
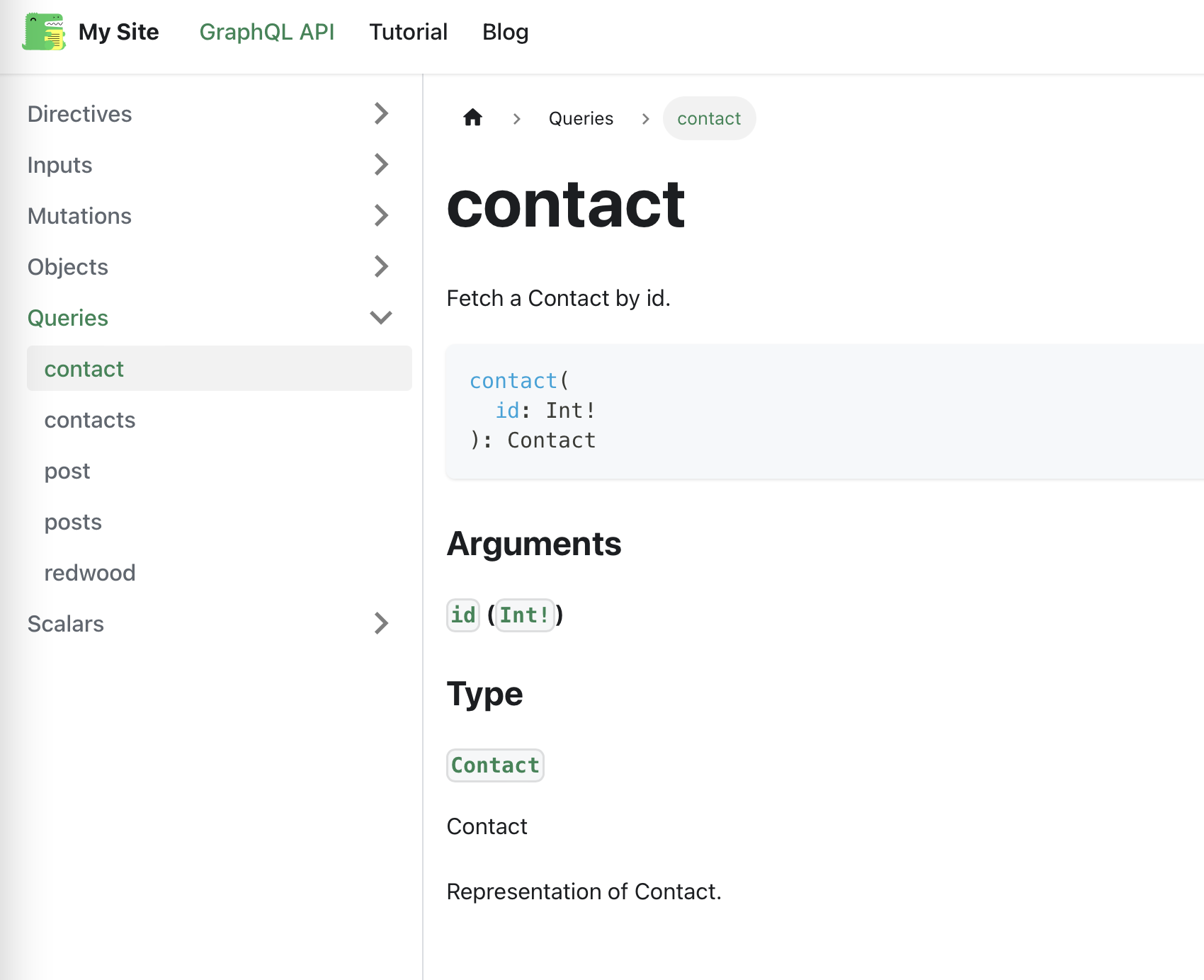
Query Example
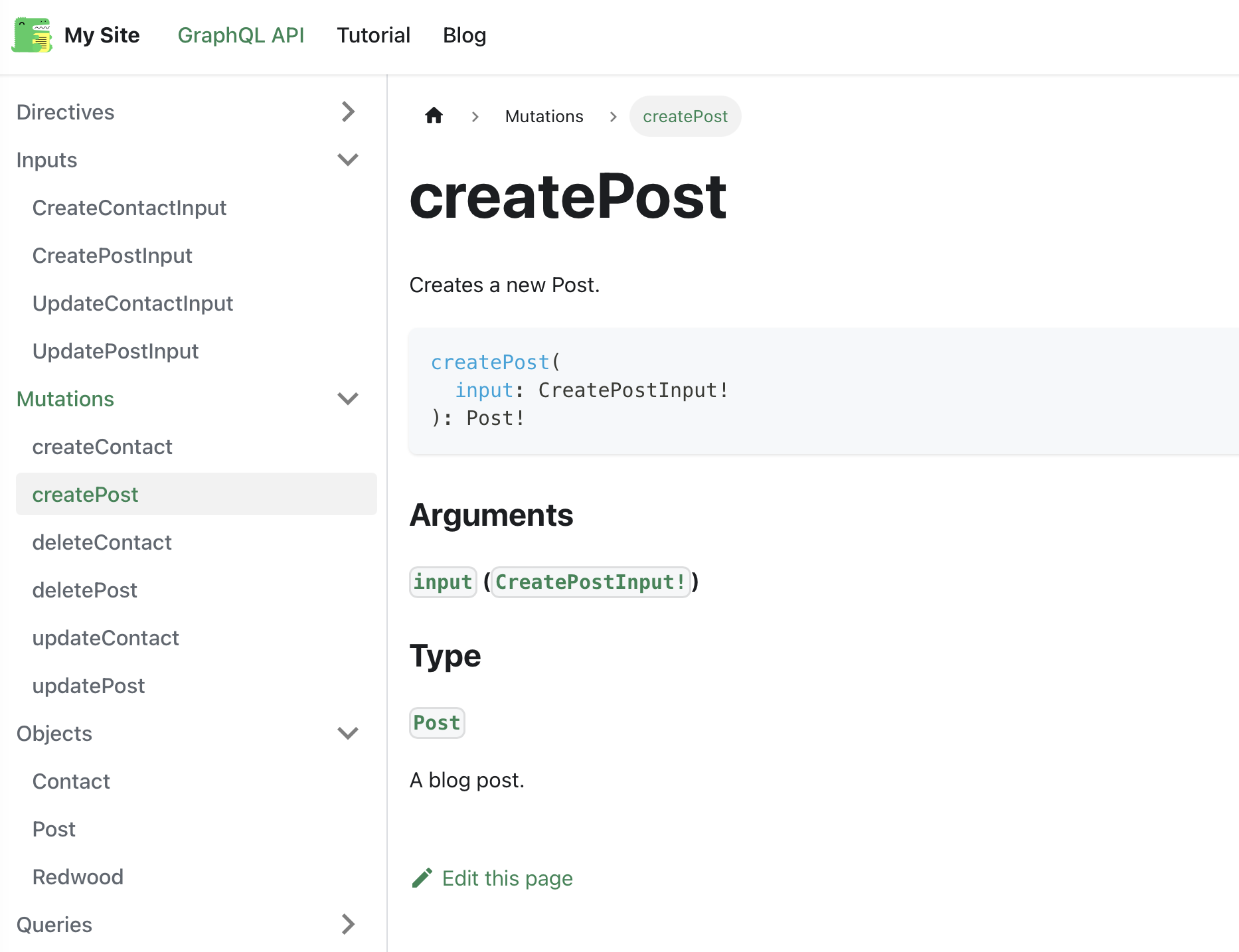
Mutation Example
Directive Example
Scalar Example
FAQ
Why Doesn't Redwood Use Something Like Nexus?
This might be one of our most frequently asked questions of all time. Here's Tom's response in the forum:
We started with Nexus, but ended up pulling it out because we felt like it was too much of an abstraction over the SDL. It’s so nice being able to just read the raw SDL to see what the GraphQL API is.
Further Reading
Eager to learn more about GraphQL? Check out some of the resources below:
- GraphQL.wtf covers most aspects of GraphQL and publishes one short video a week
- The official GraphQL Yoga (the GraphQL server powering Redwood) tutorial is the best place to get your hands on GraphQL basics
- And of course, the official GraphQL docs are great place to do a deep dive into exactly how GraphQL works