Getting Dynamic
この2つのページは素晴らしいのですが、このブログの実際の記事はどこにあるのでしょうか?次はそこを見ていきましょう。
このチュートリアルでは、ブログ記事をデータベースから取得することにします。 リレーショナル・データベースは今でも多くの複雑な(そしてさほど複雑でない)Webアプリケーションの主力であり、SQLアクセスをファーストクラスとして扱えるようにしました。Redwoodのアプリは、すべてはスキーマから始まります。
Creating the Database Schema
ブログ記事に必要なデータを決める必要があります。これについてはいずれ詳しく説明しますが、最低限、以下のようなものから始めたいと思います。
idこのブログ記事の一意な識別子 (すべてのデータベース・テーブルがこのうちの一つを持つことになります)(訳注:すべてのテーブルがUniqueなID列を持つという意味?)title"Top 10 JavaScript Frameworks Named After Trees-You Won't Believe Number 4!" のような、クリックしやすいものbodyブログ記事の実際のコンテンツcreatedAtこのレコードがデータベースで作成されたときのタイムスタンプ
データベースとの通信にはPrismaを使用します。PrismaにはMigrateという別のライブラリがあり、予測可能な方法でデータベースのスキーマを更新し、それぞれの変更のスナップショットを作成できるようになっています。それぞれの変更は migration (マイグレーション)と呼ばれ、スキーマを変更するとMigrateはマイグレーションを作成します。
まず、データベースでブログ記事のデータ構造を定義しましょう。 api/db/schema.prisma ファイルを開いて、 Post テーブルの定義を追加します( UserExample モデルのような、ファイル内にもともとある "sample" モデルはすべて削除してください)。これが終わったら、スキーマファイル全体は次のようになります:
datasource db {
provider = "sqlite"
url = env("DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
binaryTargets = "native"
}
model Post {
id Int @id @default(autoincrement())
title String
body String
createdAt DateTime @default(now())
}
これは Post という名前のテーブルが必要であり、そのテーブルには以下のものが含まれている必要があるという意味です:
Int型のidフィールドは、Prisma が@idとして使用するカラムであることを表します (他のテーブルとのリレーションを作成するため)。また@default値は Prisma の特別なautoincrement()メソッドで、新しいレコードを作成するときに DB が自動的にこれを設定する必要があることを表しますString型のtitleフィールドString型のbodyフィールドcreatedAtフィールドはDateTime型で、新しいレコードを作成するときに@defaultでnow()を設定します (したがって、アプリ内で手動で時間を設定する必要はありません。データベースが代わりに設定します)
このチュートリアルでは、なにごともシンプルにするために、IDカラムに整数を使用しています。アプリによっては、Prismaがサポートしている CUID や UUID を使用したい場合もあるでしょう。 その場合は、データ型に Int の代わりに String を使用し、 autoincrement() の代わりに cuid() または uuid() を使用することになります:
id String @id @default(cuid())
IDカラムに整数を使用すると、URLは https://redwoodblog.com/posts/eebb026c-b661-42fe-93bf-f1a373421a13 みたいなのではなく、 https://redwoodblog.com/posts/123 のようないい感じになります。
IDフィールドについて詳しくはofficial Prisma documentationを参照してください。
Migrations
それではスキーマの変更をマイグレーションとして切り取ってみましょう:
yarn rw prisma migrate dev
ここからは redwood の代わりに、より短いエイリアスである rw を使います。
このマイグレーションに名前を付けるためのプロンプトが表示されます 何をするものかを説明するものが理想的なので、"create post"(もちろん引用符はつけません)はどうでしょう。これは純粋にあなた自身のためのものです。RedwoodもPrismaもマイグレーションの名前を気にしません。古いマイグレーションを見て、特定のものを作成または変更したときに参照するだけです。
コマンドが完了すると、api/db/migrations の下に、タイムスタンプとあなたが付けたマイグレーション名を持つ新しいサブディレクトリが作成されます。その中には migration.sql という名前のファイルが一つ入っています。このファイルには、データベースの構造を schema.prisma が作成された時点のものに更新するためのSQLが含まれています。つまり、常に1つの schema.prisma ファイルがあり、そこには 今 どのようなデータベース構造にすべきかが記述されています。マイグレーションは現在の状態になるまでに行われた変更の履歴を追跡します。これは、データベース構造のバージョン管理みたいなもので、かなり便利です。
マイグレーションファイルの作成に加えて、上記のコマンドはデータベースに対してSQLを実行し、マイグレーションを "適用" します。最終結果は、ここで定義したフィールドを持つ Post という名前の新しいデータベーステーブルです。
Prisma Studio
データベースというのは、かなり抽象的なものです:データはどこにあるのでしょうか? どのように見えるのでしょうか?WebアプリでUIを作成せずに、データベースにアクセスするにはどうしたらよいでしょうか?PrismaはStudioというツールを提供しており、ナイスなWebアプリからデータベースにアクセスすることができます:

(まだデータは何もないけど)Prisma Studioを開くには、コマンドを実行します:
yarn rw prisma studio
新しいブラウザで http://localhost:5555 が開くはずで、これでデータベースのデータを直接見たり、操作したりすることができるようになりました!

"Post" をクリックすると、空のデータベーステーブルが表示されます。さっそくこのアプリでブログ記事を投稿してみましょう!
Creating a Post Editor
サイトのデザインはまだ決めていませんが、デザインチームから連絡が来たら捨ててしまうようなページをたくさん作らなくても、ブログ記事で遊べたら素晴らしいことだと思いませんか?ご想像のとおり、Redwoodに解決策がなければ、このようなシナリオを考えることはなかったでしょう!
ブログ記事のCRUD (Create、Retrieve、Update、Delete) 操作を実行するために必要なすべてを生成して、データベースに正しいフィールドがあることを確認するだけでなく、いくつかのサンプル記事を使ってページのレイアウトを始め、実際のコンテンツを見られるようにしましょう。Redwoodには、このような場合のための generator があります:
yarn rw g scaffold post
ブラウザで http://localhost:8910/posts を開いて、何があるか見てみましょう:
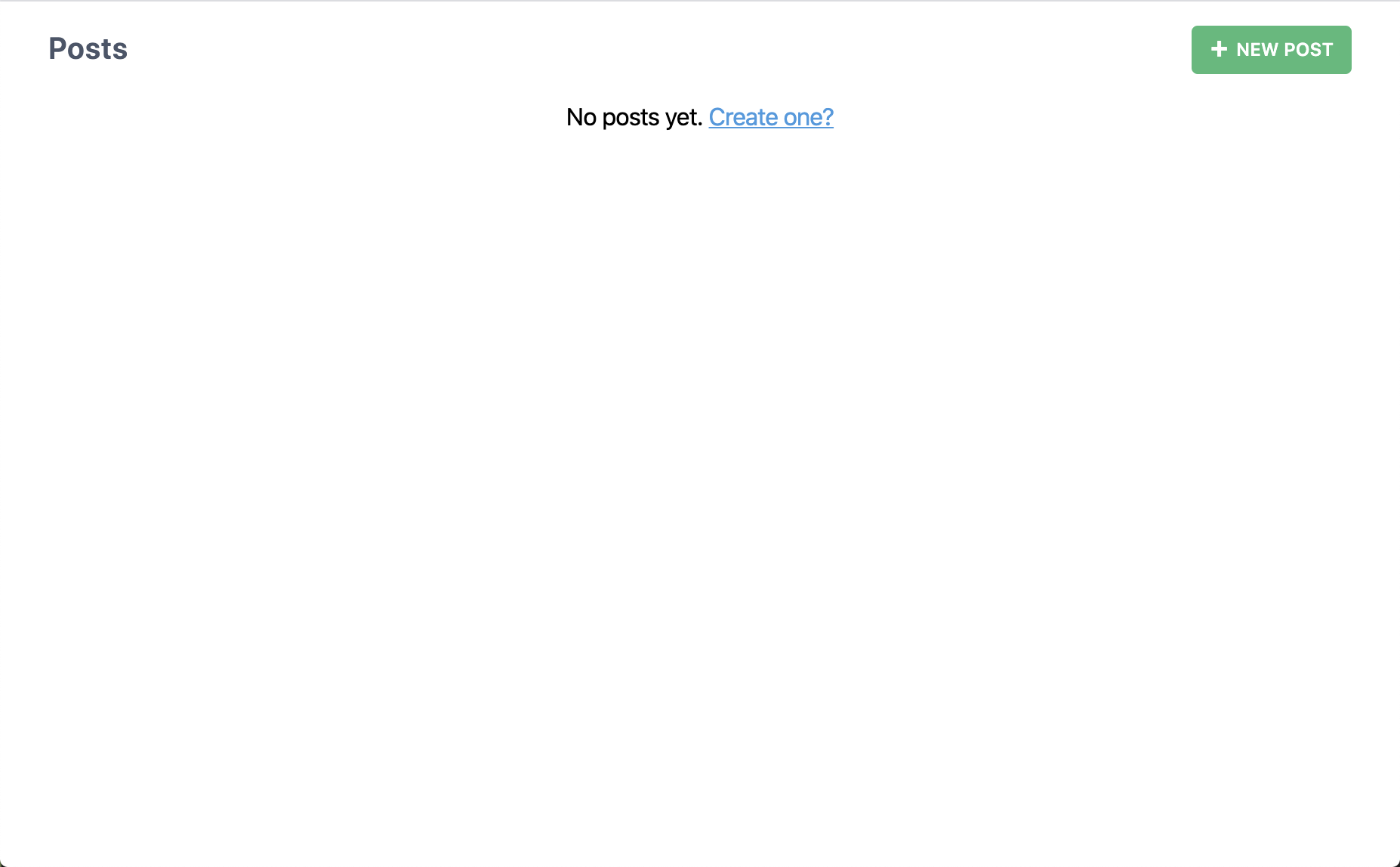
これは、ページを生成したときより、かろうじて多いですね。 "New Post" ボタンをクリックするとどうなるのでしょうか?
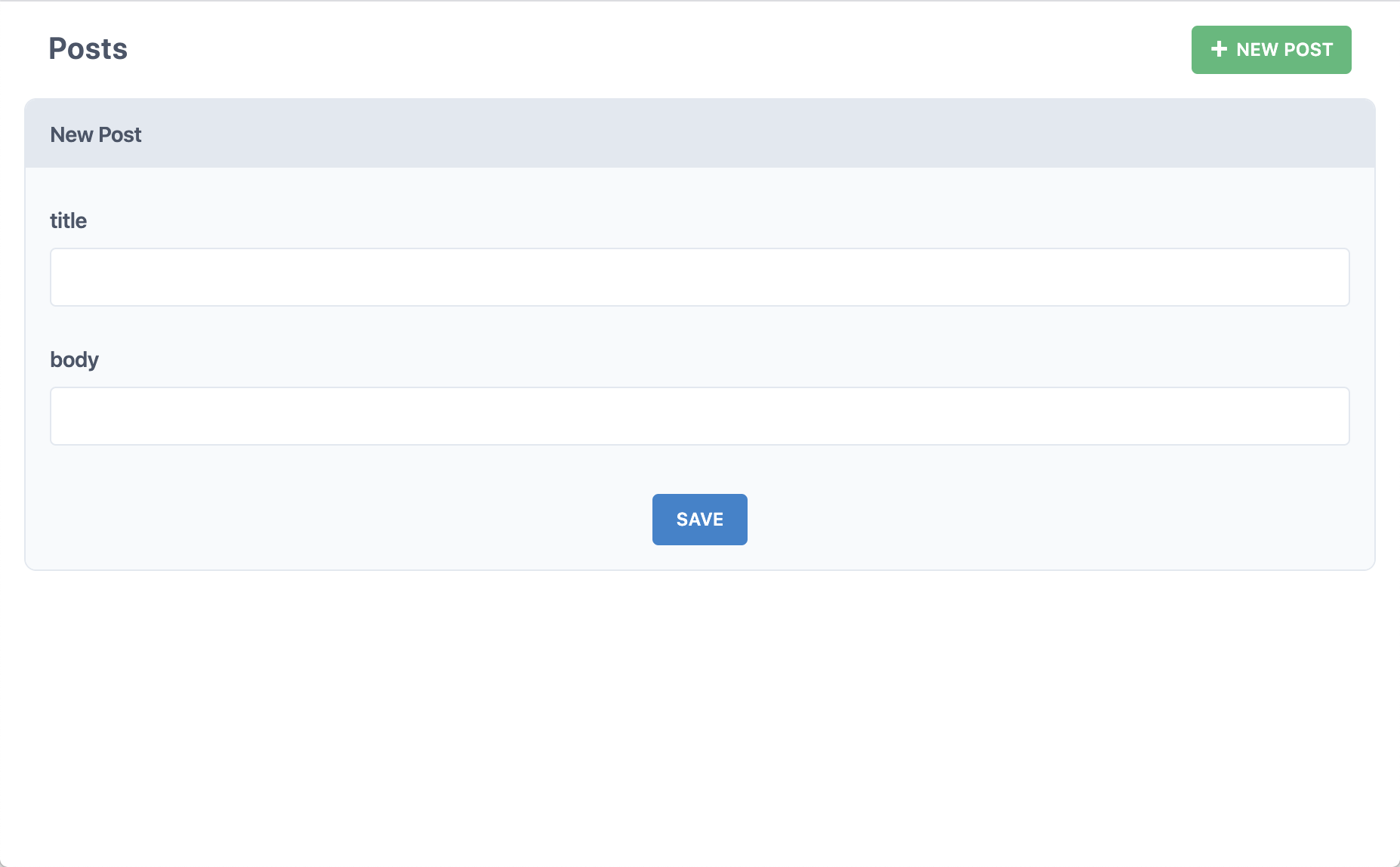
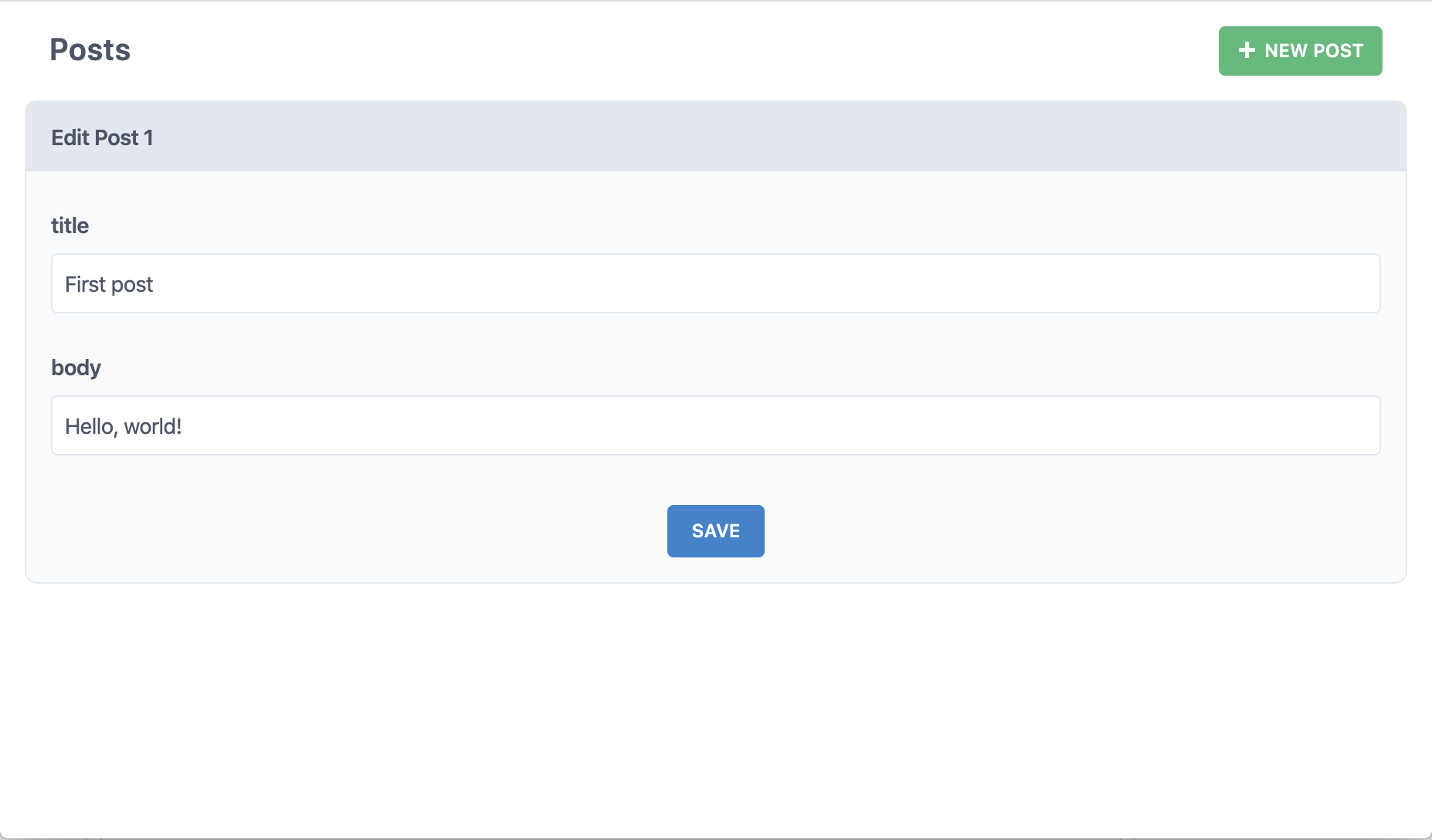
よし、これで一段落です。titleとbodyを書いて "Save" をクリックしてください。
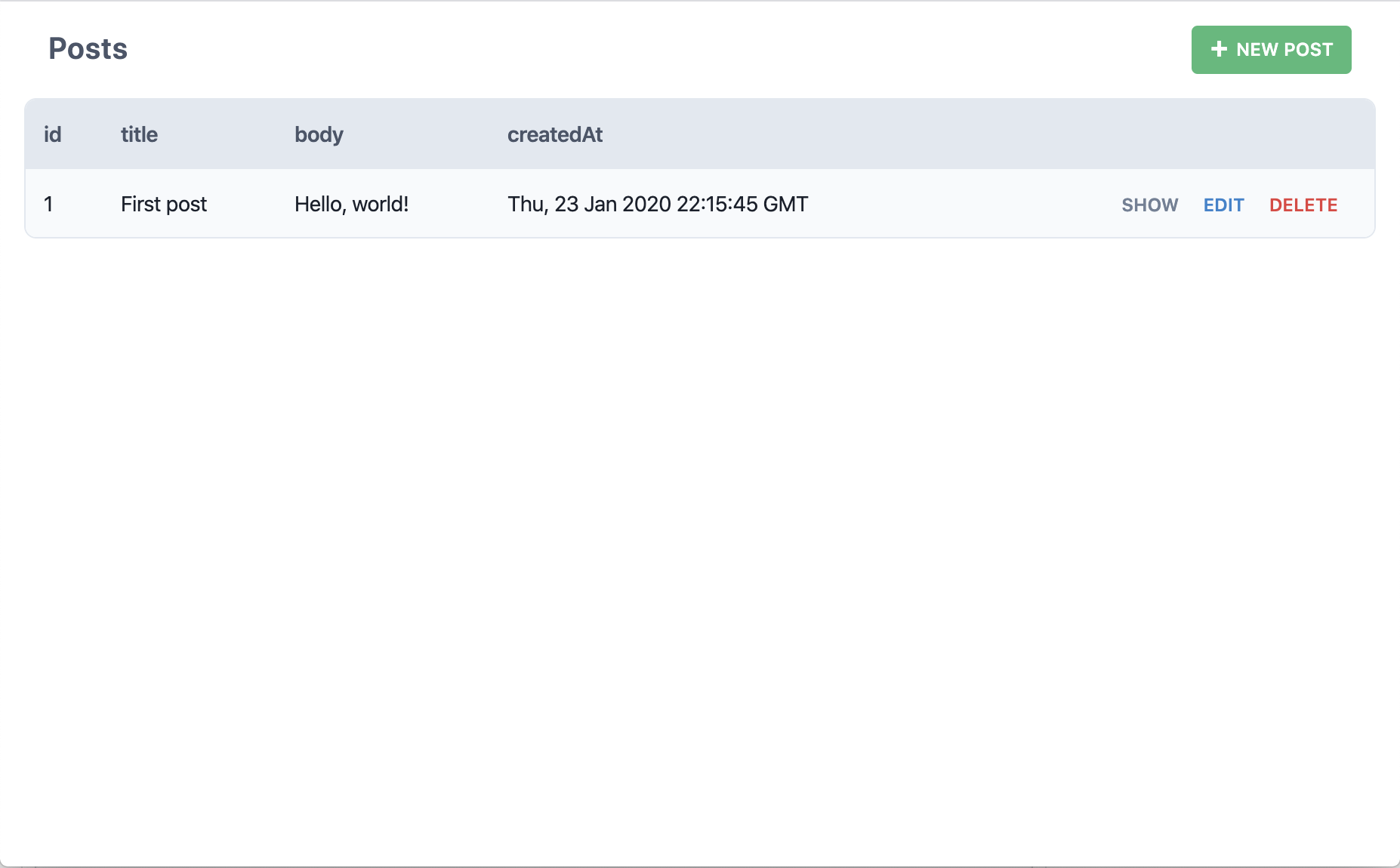
データベースにブログ記事を作成しただけでしょうか?このページでそのブログ記事を表示したのでしょうか?そしたら!もうひと記事作ってみましょう:
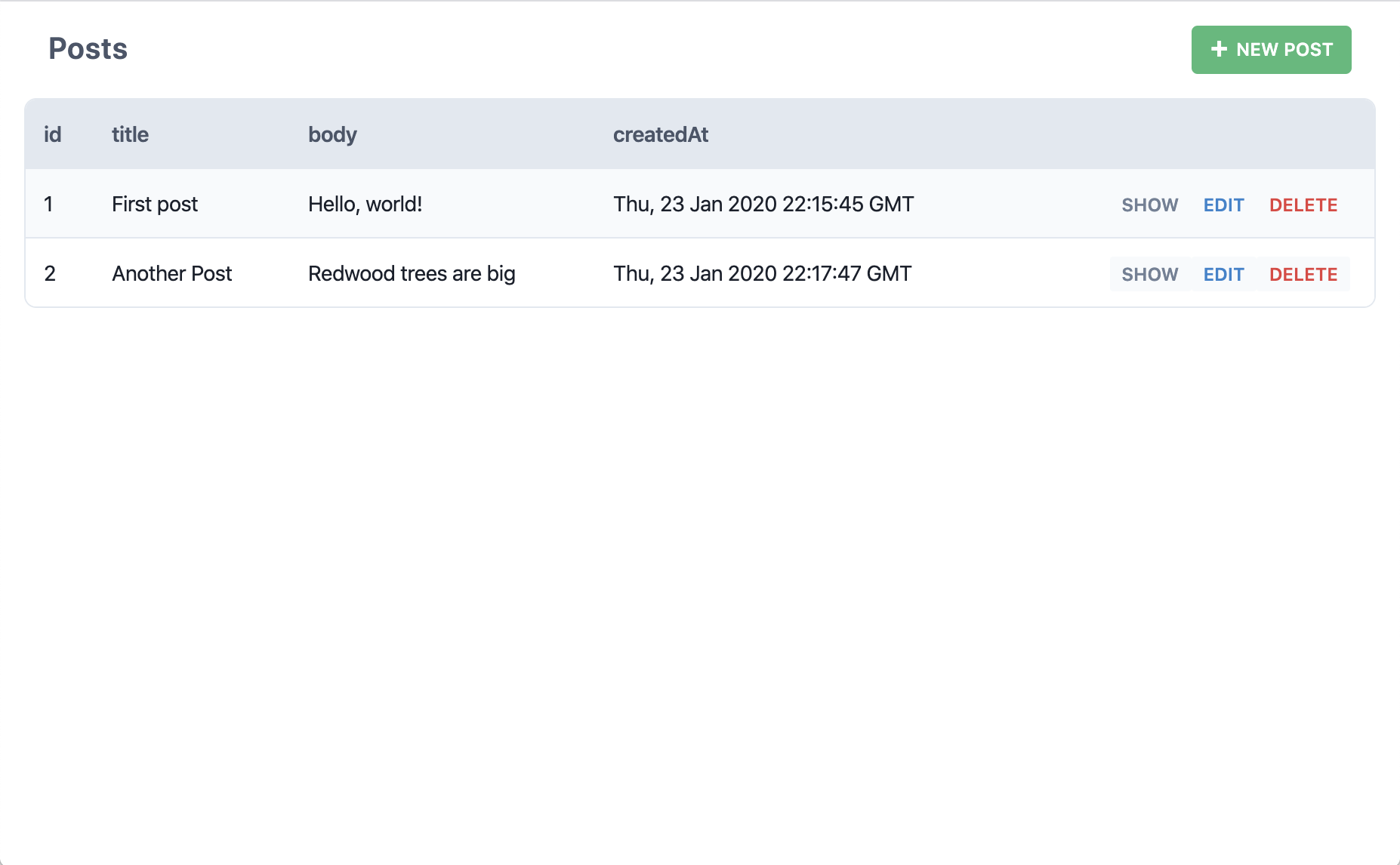
"Edit" をクリックするとどうなりますか?
"Delete" だと?
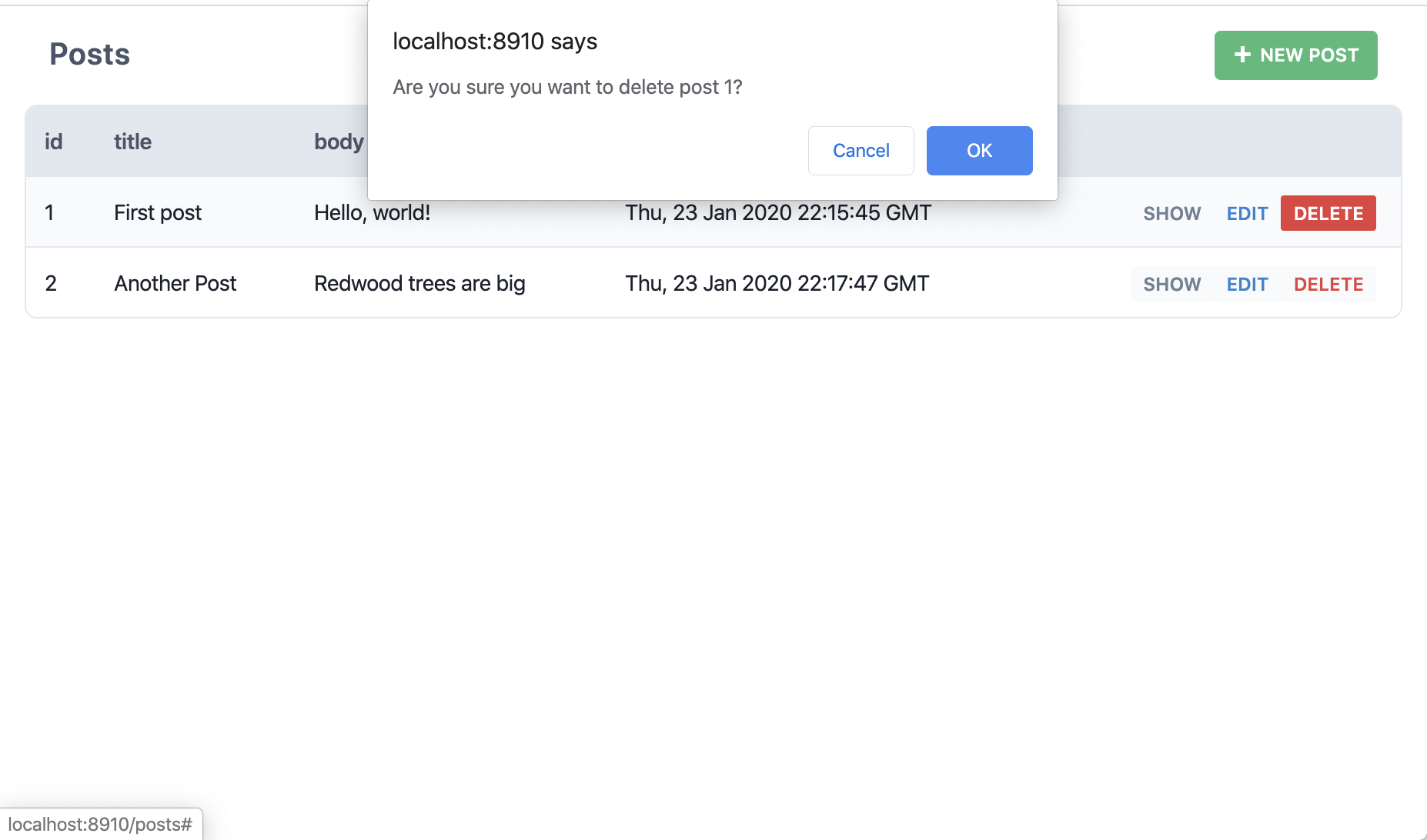
つまり、Redwoodはpostsテーブルに対するすべてのCRUDアクションを実行するために必要なすべてのページ、コンポーネント、サービスを作成しただけなのです。Prisma Studioを開いたり、ターミナルからログインしてSQLを一から書く必要はありません。Redwoodはこれらを scaffolds と呼んでいます。
もし、VSCodeに戻ったときに、生成されたPostのセル( web/src/components/Post/PostCell/PostCell.tsx )に Cannot query "posts" on type "Query" というメッセージが表示されたとしても、心配しないでください:これは、いくつかのシステムで時々見受けられます。2つの簡単な修正方法があります:
- ターミナルで
yarn rw g typesを実行する - VSCodeのGraphQLエンジンをリロードする:コマンドパレットを開き(MacはCmd+Shift+P、WindowsはCtrl+Shift+P)、 "VSCode GraphQL: Manual Restart" を見つける
以下が yarn rw g scaffold post コマンドを実行したら起きることです:
web/src/pages/Postにいくつかのページを作成する:EditPostPageブログ記事を編集するNewPostPage新しいブログ記事を作成するPostPageブログ記事を表示するPostsPageすべてのブログ記事を一覧表示する
web/src/layouts/ScaffoldLayout/ScaffoldLayout.tsxにレイアウトファイルを作成する。これらはページの見出しや "New Posts" ボタンなどの共通要素を持つページのコンテナとして機能するweb/src/Routes.tsxに、これらのページのレイアウトをPostsLayoutとして、Setコンポーネントでラップしたルートを作成するweb/src/components/Postに、3つのセルを作成するEditPostCellデータベースで編集するブログ記事を取得するPostCell表示するブログ記事を取得するPostsCellすべてのブログ記事を取得する
web/src/components/Postに、4つのコンポーネントを作成するNewPost新しいブログ記事を作成するためのフォームを表示するPost一つのブログ記事を表示するPostFormNewとEditのコンポーネントで使用される実際のフォームPostsすべてのブログ記事の一覧表を表示する
api/src/graphql/posts.sdl.tsにGraphQL のクエリとミューテーションを定義する SDL ファイルを追加するapi/src/services/posts/posts.tsにデータベースからデータを取得するためのPrismaクライアントコールを行うサービスファイルを追加する
ページとコンポーネント/セルは、Post ディレクトリにうまく収められ、整理されています。一方、レイアウトは1つしかないので、トップレベルにあります。
ふぅ〜。このように、たくさんのものがあるように見えますが、私たちはベストプラクティスに従って、実際のアプリで行うように、共通の機能を個々のコンポーネントに分離したいと思いました。もちろん、これらの機能をすべて1つのコンポーネントに詰め込むこともできますが、私たちは、これらの scaffold を、良い開発習慣の手本となるようにしたかったのです:私たちは、自分が説いたことを実践しなければならないのです!
生成されたパーツの中には複数形の名前と単数形の名前があることにお気づきでしょう。これは、より「人間的」な命名規則を使っているRuby on Railsから借用したものです:複数のものを扱う場合 (たとえば全ブログ記事のリスト) は複数形になります。複数のものを扱う場合は複数形、単一のものだけを扱う場合 (たとえば新規ブログ記事の作成) は単数形になります。話すときも自然に聞こえます: "show me a list of all the posts" と "I'm going to create a new post." のように。
ジェネレータに関する限り:
- サービスのファイル名は常に複数形
- サービスのメソッドは、複数のブログ記事を返すのか単一のブログ記事を返すのか (
postsとcreatePostの違い) によって複数形か単数形か - SDL のファイル名は複数形
- scaffolds に付属するページは、複数のブログ記事を扱うか、1つのブログ記事を扱うかによって複数形か単数形になる。
pageジェネレータを使用する場合、コマンドラインで指定された名前を使用する - レイアウトはコマンドラインで指定された名前を使用する
- コンポーネントとセルは、ページと同様に、scaffoldジェネレータで作成されるときは文脈に応じて複数形か単数形になり、それ以外はコマンドラインで与えられた名前が使われる
- scaffoldで作成されたページのルート名は、ルーティング先のページと同じように単数形または複数形になる
また、単数形か複数形かはモデル名の部分であって、単語全体ではないことに注意してください。つまり、 PostsCell や PostsPage であって、PostCells や PostPages ではありません。
自分で部品を作り始めたら、この規則に従う必要はありませんが、従うことをお勧めします。Ruby on Railsコミュニティはこの命名規則を気に入っていますが、最初にこの命名法に触れたとき、多くの人が不満を漏らしたものです!
Creating a Blog Homepage
ブログのルック&フィールが決まったら、これらのページを一つずつ置き換えていくこともできますが、その必要があるでしょうか?公開Webサイトでは、閲覧者がブログ記事を作成、編集、削除することはできないので、車輪を再発明したり、これらのページを公開Webサイトにマッチした外観に更新する必要はありません。これらのページを管理用ページとして残し、公開Webサイト用に新しいページを作成してはどうでしょうか。
一般の人が何をできるか考えれば、どんなページを作ればいいかが見えてきます:
- ブログ記事の一覧を見る(編集・削除のリンクはなし)
- 一つのブログ記事を見る
1から始めると、ブログ記事のリストを表示するための論理的な場所である HomePage がすでにあるので、このページに追加しましょう。データベースからコンテンツを取得する必要がありますが、その間、ユーザに空白の画面だけを見せたくないので(ネットワークの状態、サーバの場所などによります)、何らかの読み込みメッセージやアニメーションを表示することにします。そしてデータを取得する際にエラーが発生した場合にも対処する必要があります。また、このブログエンジンをオープンソース化し、誰かがデータベースに何もない状態で公開した場合はどうでしょうか?最初のブログ記事が作成されるまでは、白紙の状態であることを示すメッセージが表示されるとよいでしょう。
さて、最初のページでは、データの読み込み状態や、エラー、白紙の状態について心配する必要があります...よね?